このページは、ワークスペース、ファイルカテゴリ、レビュー規則リポジトリをすでに設定済みの方向けです。既存設定を使って、日常的な契約書アップロード、フィールド抽出、スマートレビューを API で実行する方法を説明します。
DocFlow の設定がまだの場合は、先に 契約レビューシナリオ(最初から設定) を参照してください。
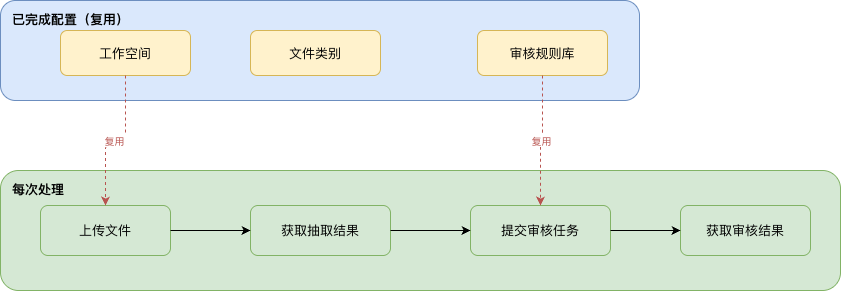
01 シナリオ概要
ワークスペース、ファイルカテゴリ、レビュー規則リポジトリは、一度設定すれば継続して再利用できます。日常的な契約書レビュー業務では、API で次の 3 ステップを繰り返します。- ファイルをアップロード: レビュー対象の購買契約書をワークスペースにアップロードします
- 抽出結果を取得: 分類認識とフィールド抽出の完了を待ち、構造化データを取得します
- スマートレビュー: 既存の規則リポジトリを指定してレビュータスクを送信し、レビュー結果を取得します
02 前提条件
このページのコードを実行する前に、次を準備してください:- 認証情報:[TextIn コンソール] から(https://www.textin.ai/console/dashboard/setting)
x-ti-app-idとx-ti-secret-codeを取得します - workspace_id:作成済みワークスペース ID(確認方法は下記)
- repo_id:設定済みレビュー規則リポジトリ ID(確認方法は下記)
- 処理対象ファイル: 今回レビューする購買契約書ファイル(PDF または Word 形式)
workspace_id の取得方法
ステップ 1:左側のワークスペース一覧で対象スペース名にマウスオーバーし、表示される「スペース情報」ボタンをクリックします。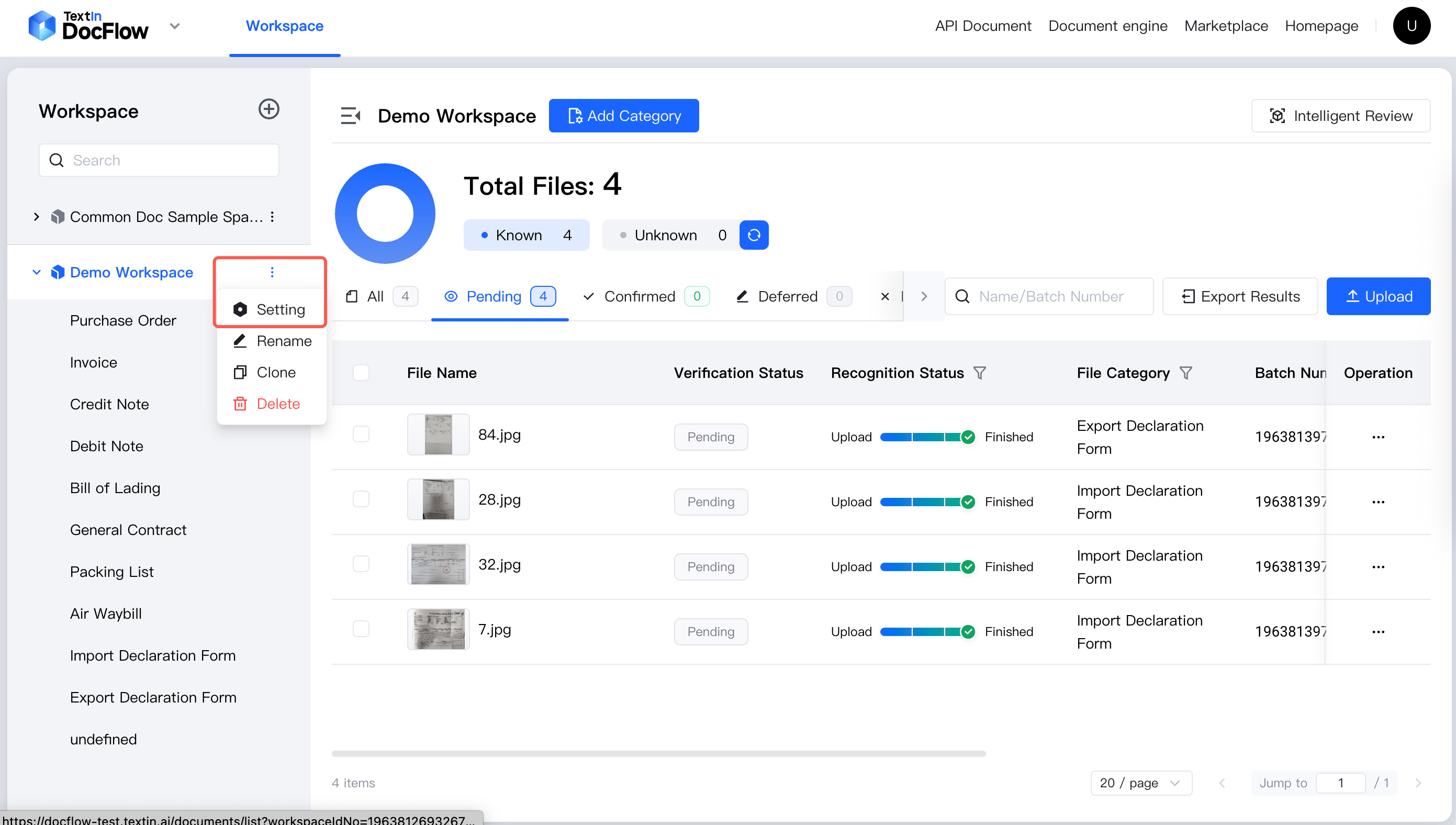
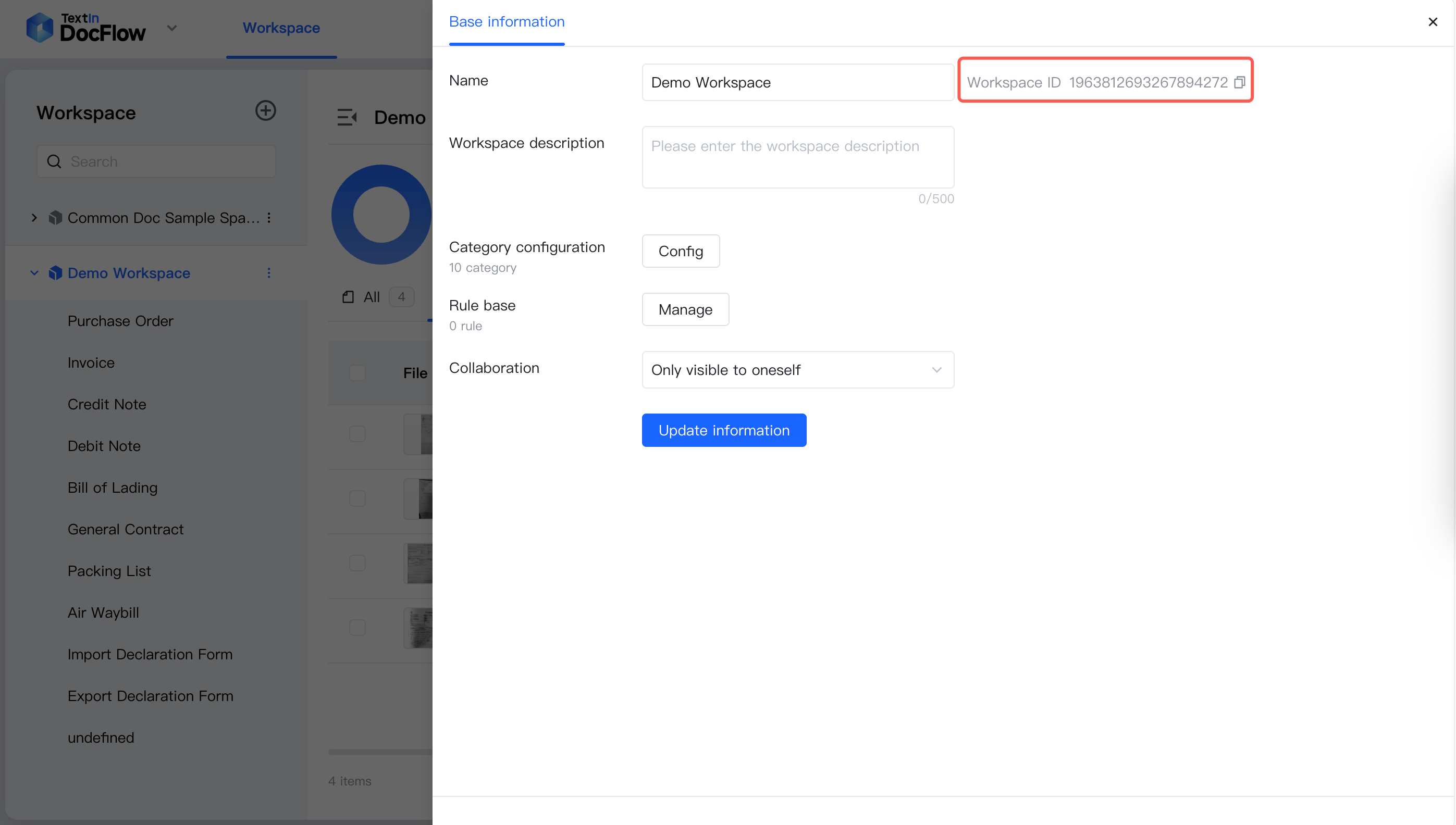
workspace_id を確認します。コピーアイコンをクリックすると直接コピーできます。
repo_id の取得方法
ステップ 1:対象ワークスペースに入り、右上の「スマートレビュー」ボタンをクリックします。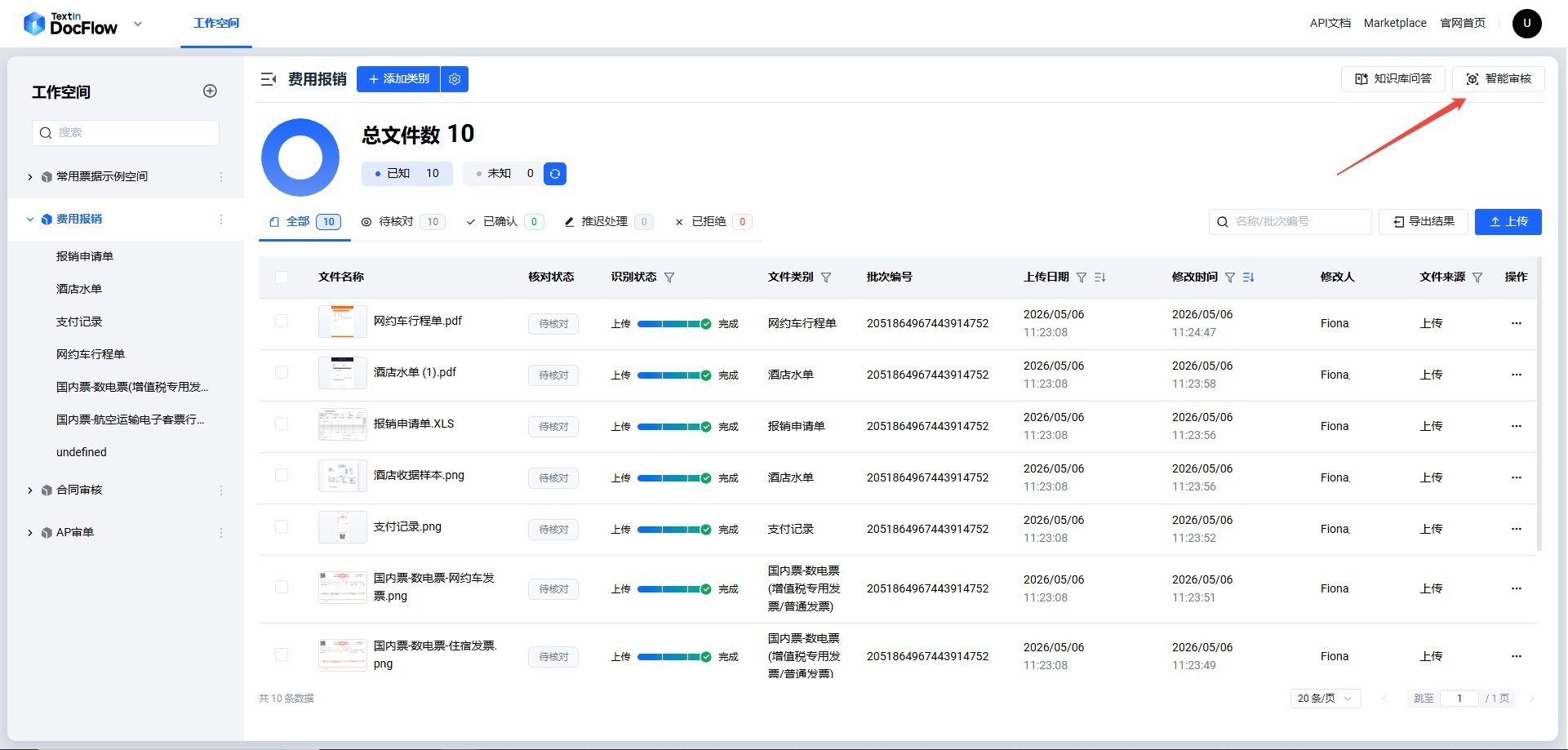
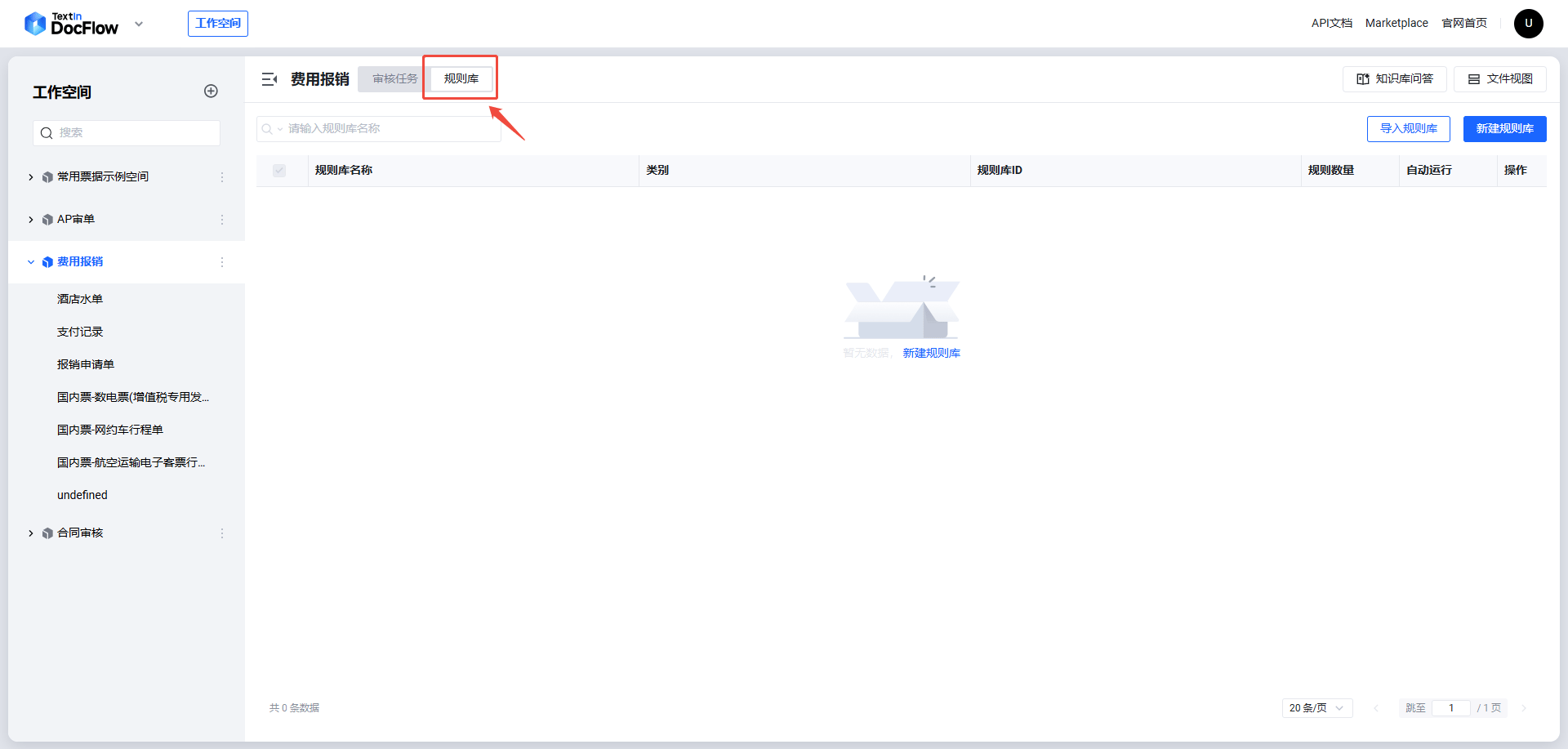
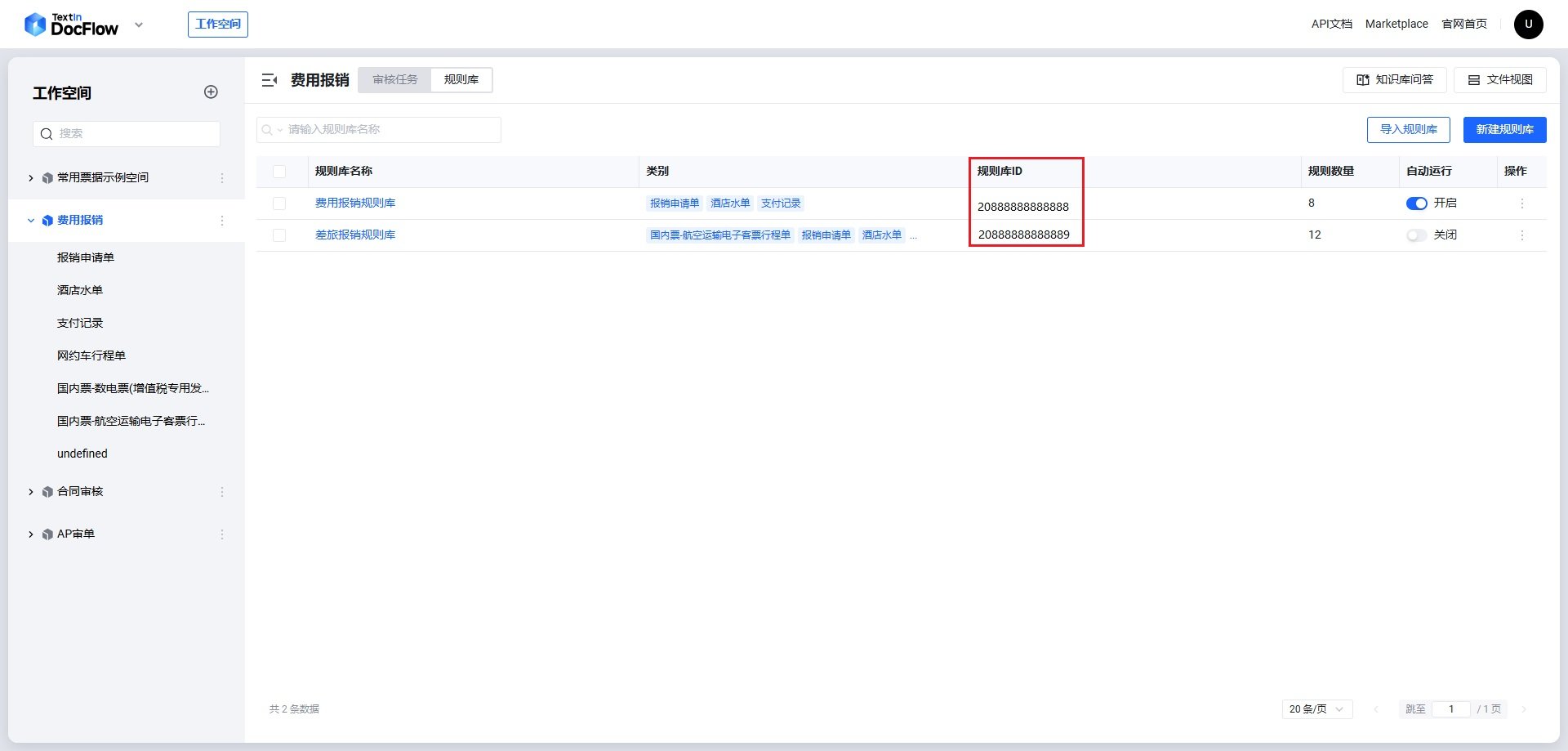
repo_id です。
03 コード構成
この例は日常処理に必要な 3 つのステップ のみを含み、コード量はゼロから設定する版より約 60% 少なくなります。API 呼び出し関数
| 関数(Python) | メソッド(Java) | 対応する API エンドポイント | 説明 |
|---|---|---|---|
upload_file | uploadFile | POST /file/upload | 非同期でファイルをアップロードし、batch_number を返します。結果取得にはポーリングが必要です |
upload_file_sync | uploadFileSync | POST /file/upload/sync | 同期でファイルをアップロードし、抽出結果を直接返します。ポーリングは不要です |
submit_review_task | submitReviewTask | POST /review/task/submit | レビュータスクを送信し、レビュー task_id を返します |
ステップ別コード説明
ステップ 1:処理対象ファイルをアップロード
ステップ 1:処理対象ファイルをアップロード
DocFlow は 2 種類のアップロードモードを提供します:
- 非同期アップロード(
file/upload):batch_numberを返します。ステップ 2 でfile/fetchをポーリングして抽出結果を取得します。一括アップロード後にまとめてポーリングするシーンに適しています。 - 同期アップロード(
file/upload/sync):認識完了までリクエストが待機し、抽出結果を直接返します(構造はfile/fetchと同じ)。ポーリングは不要で、ステップ 2 を省略できます。単一ファイルのリアルタイム処理に適しています。
方法 1:非同期アップロード(ステップ 2 のポーリングが必要)
- Python
- Java
batch_number = upload_file(WORKSPACE_ID, os.path.join(FILES_DIR, "sample_contract.docx"))
String batchNumber = uploadFile(WORKSPACE_ID, FILES_DIR + "/sample_contract.docx");
方法 2:同期アップロード(抽出結果を直接返す、ステップ 2 を省略)
- Python
- Java
def upload_file_sync(workspace_id: str, file_path: str) -> dict:
"""同期アップロード:抽出結果を直接返す、ポーリング不要。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/upload/sync"
with open(file_path, "rb") as f:
resp = requests.post(url,
params={"workspace_id": workspace_id},
files={"file": (os.path.basename(file_path), f, _mime(file_path))},
headers=_headers(), timeout=300)
data = _check(resp, "ファイルを同期アップロード")
return data["result"]["files"][0] # 戻り値構造は file/fetch と同じ
# 呼び出し例:同期アップロードして抽出結果を直接取得
file_result = upload_file_sync(WORKSPACE_ID, os.path.join(FILES_DIR, "sample_contract.docx"))
public static JsonObject uploadFileSync(String workspaceId, String filePath) throws IOException {
File file = new File(filePath);
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/upload/sync")
.newBuilder().addQueryParameter("workspace_id", workspaceId).build();
MultipartBody body = new MultipartBody.Builder().setType(MultipartBody.FORM)
.addFormDataPart("file", file.getName(),
RequestBody.create(file, MediaType.get(mimeType(file.getName()))))
.build();
Request req = new Request.Builder().url(url).headers(authHeaders()).post(body).build();
try (Response resp = HTTP.newCall(req).execute()) {
return checkResponse(resp.body().string(), "ファイルを同期アップロード")
.getAsJsonObject("result").getAsJsonArray("files")
.get(0).getAsJsonObject();
}
}
// 呼び出し例:同期アップロードして抽出結果を直接取得
JsonObject fileResult = uploadFileSync(WORKSPACE_ID, FILES_DIR + "/sample_contract.docx");
ステップ 2:抽出結果を取得(同期アップロード使用時は省略可能)
ステップ 2:抽出結果を取得(同期アップロード使用時は省略可能)
ステップ 1 で同期アップロード
file/upload/sync を使用した場合、抽出結果はすでに取得済みのため、このステップは省略できます。batch_number について file/fetch API をポーリングし、認識完了後に文書の分類結果とフィールド抽出結果を取得します。取得した結果から task_id を集め、後続のレビューに使用します。- Python
- Java
file_result = wait_for_result(WORKSPACE_ID, batch_number)
display_result(file_result)
extract_task_id = file_result.get("task_id")
JsonObject fileResult = waitForResult(WORKSPACE_ID, batchNumber, 180, 3);
displayResult(fileResult);
String extractTaskId = null;
if (fileResult.has("task_id") && !fileResult.get("task_id").isJsonNull()) {
extractTaskId = fileResult.get("task_id").getAsString();
}
ステップ 3:レビュータスクを送信して結果を取得
ステップ 3:レビュータスクを送信して結果を取得
ファイルの
task_id を review/task/submit API に渡し、既存の規則リポジトリを指定してレビューを送信します。レビュー完了後、各規則の合格/不合格と AI による判断根拠をポーリングで取得します。- Python
- Java
task_name = f"契約書レビュー_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
review_task_id = submit_review_task(WORKSPACE_ID, task_name, REPO_ID, [extract_task_id])
review_result = wait_for_review(WORKSPACE_ID, review_task_id)
display_review_result(review_result)
String taskName = "契約書レビュー_" + new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());
List<String> extractTaskIds = new ArrayList<>();
if (extractTaskId != null) extractTaskIds.add(extractTaskId);
String reviewTaskId = submitReviewTask(WORKSPACE_ID, taskName, REPO_ID, extractTaskIds);
JsonObject reviewResult = waitForReview(WORKSPACE_ID, reviewTaskId, 300, 5);
displayReviewResult(reviewResult);
04 完全な例コード
- Python
- Java
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
DocFlow 契約書レビューシナリオ例(設定済み版)
ワークスペース、ファイルカテゴリ、レビュー規則リポジトリがすべて設定済みのシナリオで使用します。
フロー:
1. アップロード待レビュー契約書ファイル
2. ポーリング抽出結果を取得、表示フィールド抽出結果
3. 送信レビュータスク
4. ポーリング取得レビュー結果、表示レビュー結論
依存関係:
pip install requests
使用前先に入力下方設定項目。
"""
import os
import time
from datetime import datetime
import requests
# ============================================================
# 設定項目 - 実際の値に置き換えてください
# ============================================================
APP_ID = "your-app-id" # TextIn コンソールの x-ti-app-id
SECRET_CODE = "your-secret-code" # TextIn コンソールの x-ti-secret-code
WORKSPACE_ID = "your-workspace-id" # 已作成的ワークスペース ID
REPO_ID = "your-repo-id" # 已設定的レビュー規則リポジトリ ID
BASE_URL = "https://docflow.textin.ai"
# 処理対象ファイルのディレクトリ(デフォルトは同梱サンプルです。自社ファイルのパスに置き換えられます)
FILES_DIR = os.path.join(
os.path.dirname(os.path.abspath(__file__)),
"..", "sample_files", "contract_review"
)
# ============================================================
# 補助関数
# ============================================================
def _headers() -> dict:
return {
"x-ti-app-id": APP_ID,
"x-ti-secret-code": SECRET_CODE,
}
def _check(resp: requests.Response, action: str) -> dict:
"""レスポンスステータスを確認し、解析済み JSON を返します。失敗時は RuntimeError を送出します。"""
data = resp.json()
if data.get("code") != 200:
raise RuntimeError(f"{action} 失敗(code={data.get('code')}): {data}")
return data
def _mime(file_path: str) -> str:
"""根据ファイル拡張子返す MIME タイプ。"""
ext = os.path.splitext(file_path)[1].lower()
return {
".png": "image/png",
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".pdf": "application/pdf",
".docx": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
".xlsx": "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
}.get(ext, "application/octet-stream")
def display_result(file_result: dict):
"""ファイルの分類結果とフィールド抽出結果を整形して出力します。"""
print("\n" + "=" * 60)
print(f"ファイル名 : {file_result.get('name')}")
print(f"分類結果 : {file_result.get('category') or '未分類'}")
data = file_result.get("data") or {}
fields = data.get("fields") or []
if fields:
print("\n── 基本情報フィールド ────────────────────────")
for f in fields:
val = f.get('value', '')
display_val = (val[:80] + "...") if len(str(val)) > 80 else val
print(f" {f.get('key', ''):<25s}: {display_val}")
def display_review_result(review_result: dict):
"""レビュータスクの結論と各規則のレビュー結果を整形して出力します。"""
STATUS_MAP = {
0: "未レビュー", 1: "レビュー合格", 2: "レビュー失敗",
3: "レビュー中", 4: "レビュー不合格", 5: "認識中",
6: "排队中", 7: "認識失敗",
}
RISK_MAP = {10: "高リスク", 20: "中リスク", 30: "低リスク"}
stats = review_result.get("statistics", {})
print("\n" + "=" * 60)
print(f"レビュータスクステータス : {STATUS_MAP.get(review_result.get('status'), '不明')}")
print(f"規則合格数 : {stats.get('pass_count', 0)}")
print(f"規則不合格数 : {stats.get('failure_count', 0)}")
for group in review_result.get("groups", []):
print(f"\n── 規則グループ:{group.get('group_name')} ───────────────────")
for rt in group.get("review_tasks", []):
result_text = STATUS_MAP.get(rt.get("review_result"), "不明")
risk_text = RISK_MAP.get(rt.get("risk_level"), "不明")
icon = "✓" if rt.get("review_result") == 1 else "✗"
print(f" {icon} [{risk_text}] {rt.get('rule_name')}: {result_text}")
reasoning = rt.get("reasoning", "")
if reasoning:
print(f" 根拠: {reasoning[:100]}{'...' if len(reasoning) > 100 else ''}")
# ============================================================
# ステップ 1:処理対象ファイルをアップロード
# REST API: POST /api/app-api/sip/platform/v2/file/upload
# ============================================================
def upload_file(workspace_id: str, file_path: str) -> str:
"""処理対象ファイルをワークスペースにアップロードし、batch_number を返します。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/upload"
with open(file_path, "rb") as f:
resp = requests.post(
url,
params={"workspace_id": workspace_id},
files={"file": (os.path.basename(file_path), f, _mime(file_path))},
headers=_headers(),
timeout=60,
)
batch_number = _check(resp, "ファイルをアップロード")["result"]["batch_number"]
print(f"[ステップ1] ファイルアップロード成功 name={os.path.basename(file_path)}"
f" batch_number={batch_number}")
return batch_number
# ============================================================
# ステップ 2:ポーリング待機抽出結果
# REST API: GET /api/app-api/sip/platform/v2/file/fetch
# ============================================================
def wait_for_result(
workspace_id: str,
batch_number: str,
timeout: int = 180,
interval: int = 3,
) -> dict:
"""
ファイル認識が完了するまでポーリングし、task_id を含むファイル結果を返します。
recognition_status: 0=待認識, 1=成功, 2=失敗
"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/fetch"
params = {"workspace_id": workspace_id, "batch_number": batch_number}
deadline = time.time() + timeout
print(f"[ステップ2] 待機処理結果(batch_number={batch_number})...", end="", flush=True)
while time.time() < deadline:
resp = requests.get(url, params=params, headers=_headers(), timeout=30)
data = _check(resp, "処理結果を取得")
files = data.get("result", {}).get("files", [])
if files:
status = files[0].get("recognition_status")
if status == 1:
print(" 完了")
return files[0]
elif status == 2:
raise RuntimeError(f"ファイル処理失敗: {files[0].get('failure_causes')}")
print(".", end="", flush=True)
time.sleep(interval)
raise TimeoutError(f"待機処理結果タイムアウト({timeout}s)")
# ============================================================
# ステップ 3:送信レビュータスク
# REST API: POST /api/app-api/sip/platform/v2/review/task/submit
# ============================================================
def submit_review_task(
workspace_id: str,
name: str,
repo_id: str,
extract_task_ids: list,
) -> str:
"""レビュータスクを送信し、レビュータスクの task_id を返します。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/review/task/submit"
payload = {
"workspace_id": workspace_id,
"name": name,
"repo_id": repo_id,
"extract_task_ids": extract_task_ids,
}
resp = requests.post(url, json=payload, headers=_headers(), timeout=30)
task_id = _check(resp, "送信レビュータスク")["result"]["task_id"]
print(f"[ステップ3] レビュータスク送信成功 task_id={task_id}")
return task_id
# ============================================================
# ステップ 4:ポーリング待機レビュー結果
# REST API: POST /api/app-api/sip/platform/v2/review/task/result
# ============================================================
def wait_for_review(
workspace_id: str,
task_id: str,
timeout: int = 300,
interval: int = 5,
) -> dict:
"""
レビュータスクが完了するまでポーリングし、レビュー結果を返します。
終了ステータス: 1=レビュー合格, 2=レビュー失敗, 4=レビュー不合格, 7=認識失敗
"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/review/task/result"
payload = {"workspace_id": workspace_id, "task_id": task_id}
deadline = time.time() + timeout
print(f"[ステップ4] 待機レビュー結果(task_id={task_id})...", end="", flush=True)
while time.time() < deadline:
resp = requests.post(url, json=payload, headers=_headers(), timeout=30)
data = _check(resp, "取得レビュー結果")
result = data.get("result", {})
if result.get("status") in (1, 2, 4, 7):
print(" 完了")
return result
print(".", end="", flush=True)
time.sleep(interval)
raise TimeoutError(f"待機レビュー結果タイムアウト({timeout}s)")
# ============================================================
# 主フロー
# ============================================================
def main():
print("=" * 60)
print(" DocFlow 契約書レビューシナリオ例(設定済み版)")
print("=" * 60)
print(f"ワークスペース: {WORKSPACE_ID}")
print(f"規則リポジトリ: {REPO_ID}")
# ----------------------------------------------------------
# ステップ 1:処理対象ファイルをアップロード
# ----------------------------------------------------------
print("\n開始処理対象ファイルをアップロード...")
batch_number = upload_file(
WORKSPACE_ID,
os.path.join(FILES_DIR, "sample_contract.docx"),
)
# ----------------------------------------------------------
# ステップ 2:抽出結果をポーリングで取得して表示
# ----------------------------------------------------------
print("\n開始処理結果を取得...")
file_result = wait_for_result(WORKSPACE_ID, batch_number)
display_result(file_result)
# ----------------------------------------------------------
# ステップ 3:送信レビュータスク
# ----------------------------------------------------------
print("\n開始レビュー...")
task_name = f"契約書レビュー_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
extract_task_ids = [file_result.get("task_id")] if file_result.get("task_id") else []
review_task_id = submit_review_task(WORKSPACE_ID, task_name, REPO_ID, extract_task_ids)
# ----------------------------------------------------------
# ステップ 4:レビュー結果をポーリングで取得して表示
# ----------------------------------------------------------
review_result = wait_for_review(WORKSPACE_ID, review_task_id)
display_review_result(review_result)
if __name__ == "__main__":
main()
package com.docflow;
import com.google.gson.*;
import okhttp3.*;
import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.*;
import java.util.concurrent.TimeUnit;
/**
* DocFlow 契約書レビューシナリオ例(設定済み版)
*
* <p>ワークスペース、ファイルカテゴリ、レビュー規則リポジトリがすべて設定済みのシナリオで使用します。
* <ol>
* <li>アップロード待レビュー契約書ファイル</li>
* <li>ポーリング抽出結果を取得、表示フィールド抽出結果</li>
* <li>送信レビュータスク</li>
* <li>ポーリング取得レビュー結果、表示レビュー結論</li>
* </ol>
*
* <p>依存関係:OkHttp 4.x、Gson(见 pom.xml)
*/
public class ContractReviewConfigured {
// ============================================================
// 設定項目 - 実際の値に置き換えてください
// ============================================================
private static final String APP_ID = "your-app-id"; // x-ti-app-id
private static final String SECRET_CODE = "your-secret-code"; // x-ti-secret-code
private static final String WORKSPACE_ID = "your-workspace-id"; // 已作成的ワークスペース ID
private static final String REPO_ID = "your-repo-id"; // 已設定的レビュー規則リポジトリ ID
private static final String BASE_URL = "https://docflow.textin.ai";
// 処理対象ファイルディレクトリ
private static final String FILES_DIR =
new File("../sample_files/contract_review").getAbsolutePath();
// ============================================================
// 共通ユーティリティ
// ============================================================
private static final OkHttpClient HTTP = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(90, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.build();
private static final Gson GSON = new GsonBuilder().disableHtmlEscaping().create();
private static final MediaType JSON_TYPE = MediaType.get("application/json; charset=utf-8");
// ============================================================
// 補助関数
// ============================================================
private static Headers authHeaders() {
return new Headers.Builder()
.add("x-ti-app-id", APP_ID)
.add("x-ti-secret-code", SECRET_CODE)
.build();
}
private static JsonObject checkResponse(String body, String action) {
JsonObject obj = JsonParser.parseString(body).getAsJsonObject();
if (obj.get("code").getAsInt() != 200) {
throw new RuntimeException(action + " 失敗: " + body);
}
return obj;
}
private static String mimeType(String filename) {
String lower = filename.toLowerCase();
if (lower.endsWith(".png")) return "image/png";
if (lower.endsWith(".jpg") || lower.endsWith(".jpeg")) return "image/jpeg";
if (lower.endsWith(".pdf")) return "application/pdf";
if (lower.endsWith(".docx")) return "application/vnd.openxmlformats-officedocument.wordprocessingml.document";
if (lower.endsWith(".xlsx")) return "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet";
return "application/octet-stream";
}
public static void displayResult(JsonObject fileResult) {
System.out.println("\n" + "=".repeat(60));
System.out.println("ファイル名 : " + str(fileResult, "name"));
System.out.println("分類結果 : " + str(fileResult, "category", "未分類"));
if (!fileResult.has("data") || fileResult.get("data").isJsonNull()) return;
JsonObject data = fileResult.getAsJsonObject("data");
JsonArray fields = jsonArray(data, "fields");
if (fields != null && fields.size() > 0) {
System.out.println("\n── 基本情報フィールド ────────────────────────");
for (JsonElement e : fields) {
JsonObject f = e.getAsJsonObject();
String val = str(f, "value");
String display = val.length() > 80 ? val.substring(0, 80) + "..." : val;
System.out.printf(" %-25s: %s%n", str(f, "key"), display);
}
}
}
public static void displayReviewResult(JsonObject reviewResult) {
Map<Integer, String> statusMap = new LinkedHashMap<>();
statusMap.put(0, "未レビュー"); statusMap.put(1, "レビュー合格"); statusMap.put(2, "レビュー失敗");
statusMap.put(3, "レビュー中"); statusMap.put(4, "レビュー不合格"); statusMap.put(5, "認識中");
statusMap.put(6, "排队中"); statusMap.put(7, "認識失敗");
Map<Integer, String> riskMap = new LinkedHashMap<>();
riskMap.put(10, "高リスク"); riskMap.put(20, "中リスク"); riskMap.put(30, "低リスク");
int status = reviewResult.get("status").getAsInt();
JsonObject stats = reviewResult.has("statistics")
? reviewResult.getAsJsonObject("statistics") : new JsonObject();
System.out.println("\n" + "=".repeat(60));
System.out.println("レビュータスクステータス : " + statusMap.getOrDefault(status, "不明"));
System.out.println("規則合格数 : " + (stats.has("pass_count") ? stats.get("pass_count").getAsInt() : 0));
System.out.println("規則不合格数 : " + (stats.has("failure_count") ? stats.get("failure_count").getAsInt() : 0));
JsonArray groups = jsonArray(reviewResult, "groups");
if (groups != null) {
for (JsonElement ge : groups) {
JsonObject group = ge.getAsJsonObject();
System.out.println("\n── 規則グループ:" + str(group, "group_name") + " ───────────────────");
JsonArray tasks = jsonArray(group, "review_tasks");
if (tasks != null) {
for (JsonElement te : tasks) {
JsonObject rt = te.getAsJsonObject();
int rv = rt.has("review_result") ? rt.get("review_result").getAsInt() : 0;
int riskLevel = rt.has("risk_level") ? rt.get("risk_level").getAsInt() : 0;
String icon = rv == 1 ? "✓" : "✗";
System.out.printf(" %s [%s] %s: %s%n",
icon, riskMap.getOrDefault(riskLevel, "不明"),
str(rt, "rule_name"), statusMap.getOrDefault(rv, "不明"));
String reasoning = str(rt, "reasoning");
if (!reasoning.isEmpty()) {
System.out.println(" 根拠: " + (reasoning.length() > 100
? reasoning.substring(0, 100) + "..." : reasoning));
}
}
}
}
}
}
// ============================================================
// ステップ 1:処理対象ファイルをアップロード
// REST API: POST /api/app-api/sip/platform/v2/file/upload
// ============================================================
public static String uploadFile(String workspaceId, String filePath) throws IOException {
File file = new File(filePath);
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/upload")
.newBuilder()
.addQueryParameter("workspace_id", workspaceId)
.build();
MultipartBody body = new MultipartBody.Builder()
.setType(MultipartBody.FORM)
.addFormDataPart("file", file.getName(),
RequestBody.create(file, MediaType.get(mimeType(file.getName()))))
.build();
Request req = new Request.Builder()
.url(url).headers(authHeaders())
.post(body)
.build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject data = checkResponse(resp.body().string(), "ファイルをアップロード[" + file.getName() + "]");
String batchNumber = data.getAsJsonObject("result").get("batch_number").getAsString();
System.out.println("[ステップ1] ファイルアップロード成功 name=" + file.getName()
+ " batch_number=" + batchNumber);
return batchNumber;
}
}
// ============================================================
// ステップ 2:ポーリング待機抽出結果
// REST API: GET /api/app-api/sip/platform/v2/file/fetch
// ============================================================
public static JsonObject waitForResult(
String workspaceId, String batchNumber,
int timeoutSec, int intervalSec) throws IOException, InterruptedException {
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/fetch")
.newBuilder()
.addQueryParameter("workspace_id", workspaceId)
.addQueryParameter("batch_number", batchNumber)
.build();
long deadline = System.currentTimeMillis() + (long) timeoutSec * 1000;
System.out.print("[ステップ2] 待機処理結果(batch_number=" + batchNumber + ")...");
while (System.currentTimeMillis() < deadline) {
Request req = new Request.Builder()
.url(url).headers(authHeaders()).get().build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject data = checkResponse(resp.body().string(), "処理結果を取得");
JsonArray files = data.getAsJsonObject("result").getAsJsonArray("files");
if (files != null && files.size() > 0) {
JsonObject file = files.get(0).getAsJsonObject();
int status = file.get("recognition_status").getAsInt();
if (status == 1) { System.out.println(" 完了"); return file; }
if (status == 2) {
String cause = file.has("failure_causes")
? file.get("failure_causes").getAsString() : "不明原因";
throw new RuntimeException("ファイル処理失敗: " + cause);
}
}
}
System.out.print(".");
Thread.sleep((long) intervalSec * 1000);
}
throw new RuntimeException("待機処理結果タイムアウト(" + timeoutSec + "s)");
}
// ============================================================
// ステップ 3:送信レビュータスク
// REST API: POST /api/app-api/sip/platform/v2/review/task/submit
// ============================================================
public static String submitReviewTask(
String workspaceId, String name, String repoId,
List<String> extractTaskIds) throws IOException {
String url = BASE_URL + "/api/app-api/sip/platform/v2/review/task/submit";
JsonObject payload = new JsonObject();
payload.addProperty("workspace_id", workspaceId);
payload.addProperty("name", name);
payload.addProperty("repo_id", repoId);
JsonArray ids = new JsonArray();
extractTaskIds.forEach(ids::add);
payload.add("extract_task_ids", ids);
Request req = new Request.Builder()
.url(url).headers(authHeaders())
.post(RequestBody.create(GSON.toJson(payload), JSON_TYPE))
.build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject data = checkResponse(resp.body().string(), "送信レビュータスク");
String taskId = data.getAsJsonObject("result").get("task_id").getAsString();
System.out.println("[ステップ3] レビュータスク送信成功 task_id=" + taskId);
return taskId;
}
}
// ============================================================
// ステップ 4:ポーリング待機レビュー結果
// REST API: POST /api/app-api/sip/platform/v2/review/task/result
// ============================================================
public static JsonObject waitForReview(
String workspaceId, String taskId,
int timeoutSec, int intervalSec) throws IOException, InterruptedException {
String url = BASE_URL + "/api/app-api/sip/platform/v2/review/task/result";
JsonObject payload = new JsonObject();
payload.addProperty("workspace_id", workspaceId);
payload.addProperty("task_id", taskId);
long deadline = System.currentTimeMillis() + (long) timeoutSec * 1000;
System.out.print("[ステップ4] 待機レビュー結果(task_id=" + taskId + ")...");
while (System.currentTimeMillis() < deadline) {
Request req = new Request.Builder()
.url(url).headers(authHeaders())
.post(RequestBody.create(GSON.toJson(payload), JSON_TYPE))
.build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject data = checkResponse(resp.body().string(), "取得レビュー結果");
JsonObject result = data.getAsJsonObject("result");
int status = result.get("status").getAsInt();
if (status == 1 || status == 2 || status == 4 || status == 7) {
System.out.println(" 完了");
return result;
}
}
System.out.print(".");
Thread.sleep((long) intervalSec * 1000);
}
throw new RuntimeException("待機レビュー結果タイムアウト(" + timeoutSec + "s)");
}
// ============================================================
// 主フロー
// ============================================================
public static void main(String[] args) throws Exception {
System.out.println("=".repeat(60));
System.out.println(" DocFlow 契約書レビューシナリオ例(設定済み版)");
System.out.println("=".repeat(60));
System.out.println("ワークスペース: " + WORKSPACE_ID);
System.out.println("規則リポジトリ: " + REPO_ID);
// ステップ 1:処理対象ファイルをアップロード
System.out.println("\n開始処理対象ファイルをアップロード...");
String batchNumber = uploadFile(WORKSPACE_ID, FILES_DIR + "/sample_contract.docx");
// ステップ 2:抽出結果を取得して表示
System.out.println("\n開始処理結果を取得...");
JsonObject fileResult = waitForResult(WORKSPACE_ID, batchNumber, 180, 3);
displayResult(fileResult);
// ステップ 3:送信レビュータスク
System.out.println("\n開始レビュー...");
String taskName = "契約書レビュー_" + new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());
List<String> extractTaskIds = new ArrayList<>();
if (fileResult.has("task_id") && !fileResult.get("task_id").isJsonNull()) {
extractTaskIds.add(fileResult.get("task_id").getAsString());
}
String reviewTaskId = submitReviewTask(WORKSPACE_ID, taskName, REPO_ID, extractTaskIds);
// ステップ 4:ポーリング取得レビュー結果
JsonObject reviewResult = waitForReview(WORKSPACE_ID, reviewTaskId, 300, 5);
displayReviewResult(reviewResult);
}
// ============================================================
// 私有工具方法
// ============================================================
private static String str(JsonObject obj, String key) { return str(obj, key, ""); }
private static String str(JsonObject obj, String key, String defaultVal) {
if (obj == null || !obj.has(key) || obj.get(key).isJsonNull()) return defaultVal;
return obj.get(key).getAsString();
}
private static JsonArray jsonArray(JsonObject obj, String key) {
if (obj == null || !obj.has(key) || obj.get(key).isJsonNull()) return null;
JsonElement e = obj.get(key);
return e.isJsonArray() ? e.getAsJsonArray() : null;
}
}
05 完全な例コードダウンロード
完全な実行可能コード(Python 版、Java 版)は、ドキュメントリポジトリのexamples/ ディレクトリに同梱されています:
examples/
├── python/
│ ├── contract_review_configured.py # Python 完全な例(設定済み版)
│ ├── requirements.txt
│ └── README.md
├── java/
│ ├── src/main/java/com/docflow/
│ │ └── ContractReviewConfigured.java # Java 完全な例(設定済み版)
│ ├── pom.xml
│ └── README.md
└── sample_files/
└── contract_review/
└── sample_contract.docx
Python 例
確認 Python 完全な例コード
Java 例
確認 Java 完全な例コード
06 実行例
- Python
- Java
環境要件:Python 3.8+1. 依存関係をインストール2. 入力設定開き 3. 実行
cd examples/python
pip install -r requirements.txt
contract_review_configured.py、入力ファイル上部的設定項目:APP_ID = "your-app-id" # x-ti-app-id
SECRET_CODE = "your-secret-code" # x-ti-secret-code
WORKSPACE_ID = "your-workspace-id" # 已作成的ワークスペース ID
REPO_ID = "your-repo-id" # 已設定的レビュー規則リポジトリ ID
python contract_review_configured.py
環境要件:JDK 11+、Maven 3.6+1. 入力設定開き 2. ビルドして実行
src/main/java/com/docflow/ContractReviewConfigured.java、入力ファイル上部的設定項目:private static final String APP_ID = "your-app-id";
private static final String SECRET_CODE = "your-secret-code";
private static final String WORKSPACE_ID = "your-workspace-id";
private static final String REPO_ID = "your-repo-id";
cd examples/java
mvn compile exec:java -Dexec.mainClass="com.docflow.ContractReviewConfigured"
実行に成功したら、DocFlow Web ページ にログインし、対象ワークスペースで各ファイルの分類結果、フィールド抽出結果、スマートレビュー結果を確認できます。コードの出力結果との照合にも役立ちます。
想定されるコンソール出力
============================================================
DocFlow 契約書レビューシナリオ例(設定済み版)
============================================================
ワークスペース: <workspace_id>
規則リポジトリ: <repo_id>
開始処理対象ファイルをアップロード...
[ステップ1] ファイルアップロード成功 name=sample_contract.docx batch_number=<batch_number>
開始処理結果を取得...
[ステップ2] 待機処理結果(batch_number=<batch_number>)........... 完了
============================================================
ファイル名 : sample_contract.docx
分類結果 : 購買契約書
── 基本情報フィールド ────────────────────────
契約書番号 : CG-123456
契約書名称 : 合合情報購買契約書
甲正式名称 : 上海合合情報科技股份有限公司
甲住所 : 上海市静安区万荣路1268号云立方A座11层
乙正式名称 : 上海一二三有限公司
乙住所 : 上海市延安东路1111号
締結日 : 2025年9月25日
税込合計金額(大文字表記) : 伍万元整
税率 : 13%
支払サイト : 60日
支払方法 : 转账形式
履行期限 : 2025年10月底-11月初
...
開始レビュー...
[ステップ3] レビュータスク送信成功 task_id=<task_id>
[ステップ4] 待機レビュー結果(task_id=<task_id>).... 完了
============================================================
レビュータスクステータス : レビュー不合格
規則合格数 : 3
規則不合格数 : 1
── 規則グループ:契約書条項コンプライアンス性チェック ───────────────────
✓ [高リスク] 署名・押印完全性チェック: レビュー合格
✓ [中リスク] 必要条項完全性: レビュー合格
✗ [高リスク] 支払条項妥当性: レビュー不合格
根拠: 契約書取り決めます收到請求書后60日内支付全款、支払サイト超出公司规定的30天基準
✓ [低リスク] 紛争解決条項: レビュー合格
...
07 結果説明
抽出結果
処理完了後、契約書ファイルの分類結果とフィールド抽出結果が返されます。フィールド抽出結果はdata.fields[] に格納され、各フィールドには key、value、座標情報 position が含まれます(原文のハイライト表示に利用できます)。契約書シナリオでは Model 2(複雑文書理解) を使用することで、長文書の理解とフィールド抽出の精度を高められます。
以下は、購買契約書サンプルファイルに対する実際の API レスポンス例です(file/fetch から取得。一部の position 座標とフィールドは省略しています)。
sample_contract.docx
sample_contract.docx
{
"name": "sample_contract.docx",
"format": "docx",
"category": "購買契約書",
"recognition_status": 1,
"duration_ms": 44945,
"total_page_num": 4,
"data": {
"fields": [
{ "key": "契約書番号", "value": "CG-123456" },
{ "key": "契約書名称", "value": "合合情報購買契約書" },
{ "key": "甲正式名称", "value": "上海合合情報科技股份有限公司" },
{ "key": "甲住所", "value": "上海市静安区万荣路1268号云立方A座11层" },
{ "key": "乙正式名称", "value": "上海一二三有限公司" },
{ "key": "乙住所", "value": "上海市延安东路1111号" },
{ "key": "締結日", "value": "2025年9月25日" },
{ "key": "税込合計金額(大文字表記)", "value": "伍万元整" },
{ "key": "税率", "value": "13%" },
{ "key": "支払サイト", "value": "60日" },
{ "key": "支払方法", "value": "转账形式" },
{ "key": "支払条件", "value": "甲收到全部货物且検収合格后、乙向甲开具全额增值税专用請求書、甲收到請求書后60日内支付全款" },
{ "key": "履行期限", "value": "2025年10月底-11月初" },
{ "key": "履行地点", "value": "以甲告知为准" },
{ "key": "対象名称", "value": "交换机;交换机;光模块;光纤跳线" },
{ "key": "対象数量/サービス范围", "value": "1;1;40;13" },
{ "key": "受取口座情報", "value": "开户名:上海一二三有限公司;开户銀行:上海浦东发展銀行陆家嘴支行;账号:98060154711111111" },
{ "key": "契約書部数", "value": "壹式【贰】份、甲乙双方各执【壹】份" },
{ "key": "発効条件", "value": "经双方盖章后生效" },
{ "key": "紛争解決方法", "value": "双方同意将争议送信契約書订立地上海市静安区人民法院诉讼解决" }
],
"stamps": [],
"handwritings": []
}
}
レビュー結果
レビュー完了後、review/task/result API から次の情報を取得できます:
status:任务全体ステータス(1=レビュー合格、4=レビュー不合格、2=レビュー失敗)statistics:規則合格数、不合格数汇总groups[].review_tasks[]:各規則的詳細レビュー結果、含む:review_result:この規則的レビュー結論(1=合格、4=不合格)reasoning:AI によるレビュー根拠の説明anchors:原文内で根拠となる座標位置(ハイライト表示に利用できます)
{
"task_id": "31415926",
"task_name": "契約書レビュー_20250925_143022",
"status": 1,
"statistics": { "pass_count": 5, "failure_count": 0, "error_count": 0 },
"groups": [
{
"group_name": "基本条項完全性",
"review_tasks": [
{
"rule_name": "必須条項完全性チェック",
"risk_level": 10,
"review_result": 1,
"reasoning": "契約書番号 CG-123456、甲"上海合合情報科技股份有限公司"、乙"上海一二三有限公司"、締結日 2025年9月25日、税込合計金額"伍万元整"など必須条項はいずれも入力済み、レビュー合格。"
},
{
"rule_name": "契約書金額と税率コンプライアンス",
"risk_level": 10,
"review_result": 1,
"reasoning": "税込合計金額"伍万元整"、税率 13%、符合增值税一般纳税人货物購買税率要求、レビュー合格。"
}
]
},
{
"group_name": "財務条項コンプライアンス性",
"review_tasks": [
{
"rule_name": "支払条項明確性",
"risk_level": 10,
"review_result": 1,
"reasoning": "支払条件明确规定"甲收到全部货物且検収合格后、乙向甲开具全额增值税专用請求書、甲收到請求書后60日内支付全款"、条項清晰、レビュー合格。"
},
{
"rule_name": "受取口座情報完全性",
"risk_level": 20,
"review_result": 1,
"reasoning": "受取口座情報含む开户名、开户銀行、账号三项、情報完全な、レビュー合格。"
}
]
},
{
"group_name": "法務条項レビュー",
"review_tasks": [
{
"rule_name": "違約金条項存在性",
"risk_level": 10,
"review_result": 1,
"reasoning": "契約書含む明确的違約金条項、乙逾期交货按契約書合計金額万分之五/日计算違約金、レビュー合格。"
}
]
}
]
}