このページは、ワークスペース、ファイルカテゴリ、レビュー規則リポジトリをすでに設定済みの方向けです。既存設定を使って、日常的なファイルアップロード、フィールド抽出、スマートレビューを API で実行する方法を説明します。
DocFlow の設定がまだの場合は、先に 経費精算シナリオ(最初から設定) を参照してください。
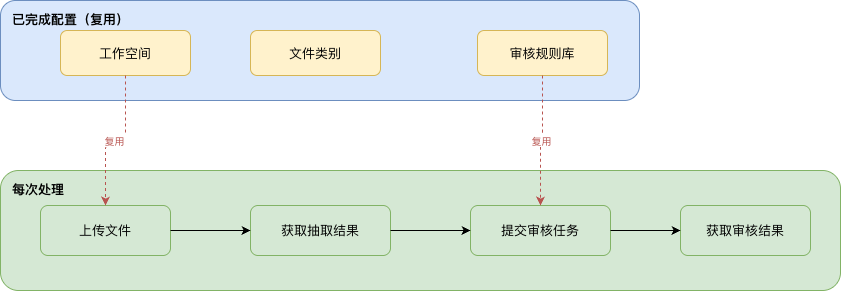
01 シナリオ概要
ワークスペース、ファイルカテゴリ、レビュー規則リポジトリは、一度設定すれば継続して再利用できます。日常業務では、API で次の 3 ステップを繰り返します。- ファイルをアップロード:新しい経費精算書類をワークスペースへアップロードします
- 抽出結果を取得: 分類認識とフィールド抽出の完了を待ち、構造化データを取得します
- スマートレビュー: 既存の規則リポジトリを指定してレビュータスクを送信し、レビュー結果を取得します
02 前提条件
このページのコードを実行する前に、次を準備してください:- 認証情報:[TextIn コンソール] から(https://www.textin.ai/console/dashboard/setting)
x-ti-app-idとx-ti-secret-codeを取得します - workspace_id:作成済みワークスペース ID(確認方法は下記)
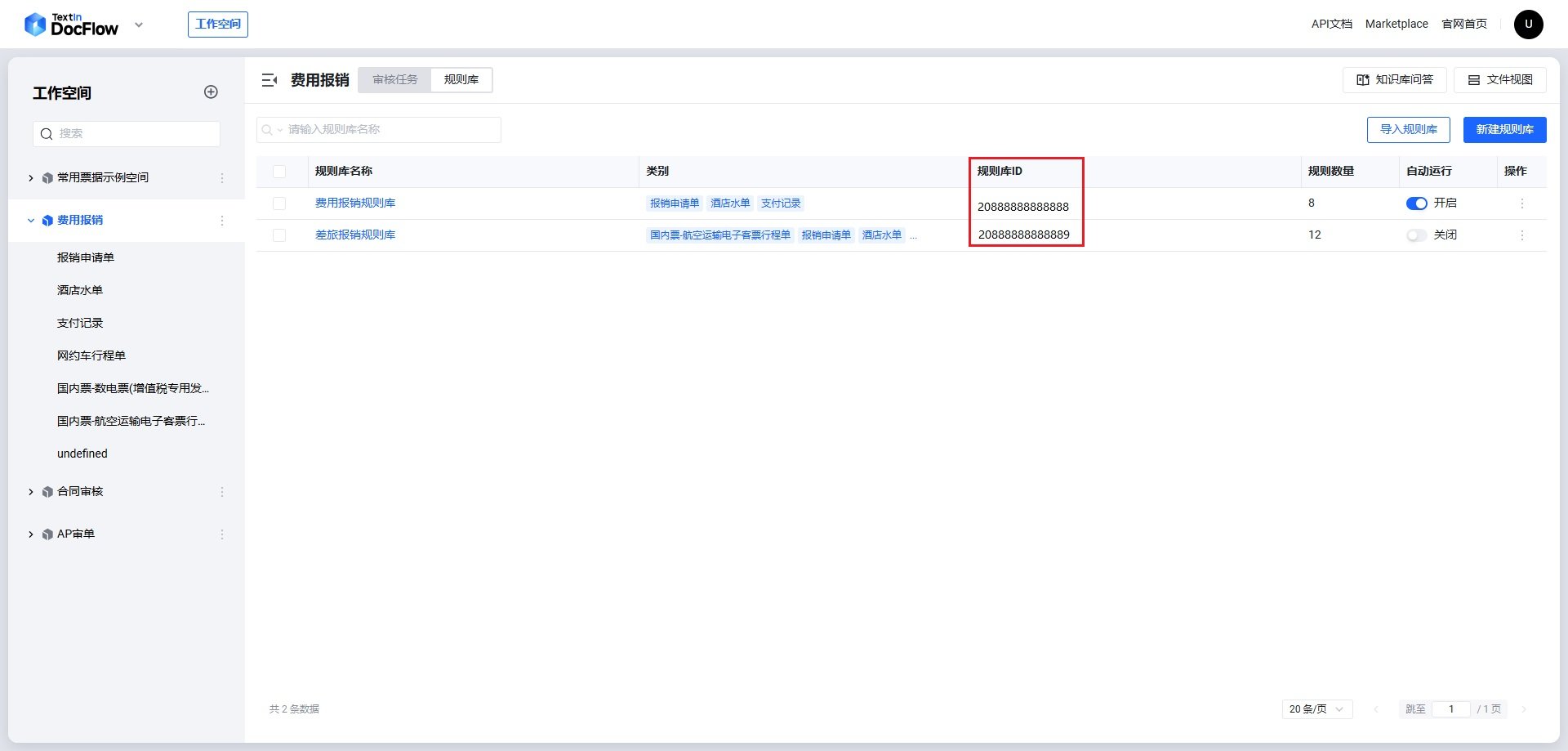
- repo_id:設定済みレビュー規則リポジトリ ID(確認方法は下記)
- 処理対象ファイル:今回処理する経費精算書類、例:経費申請書、ホテル明細、支払記録など
workspace_id の取得方法
ステップ 1:左側のワークスペース一覧で対象スペース名にマウスオーバーし、表示される「スペース情報」ボタンをクリックします。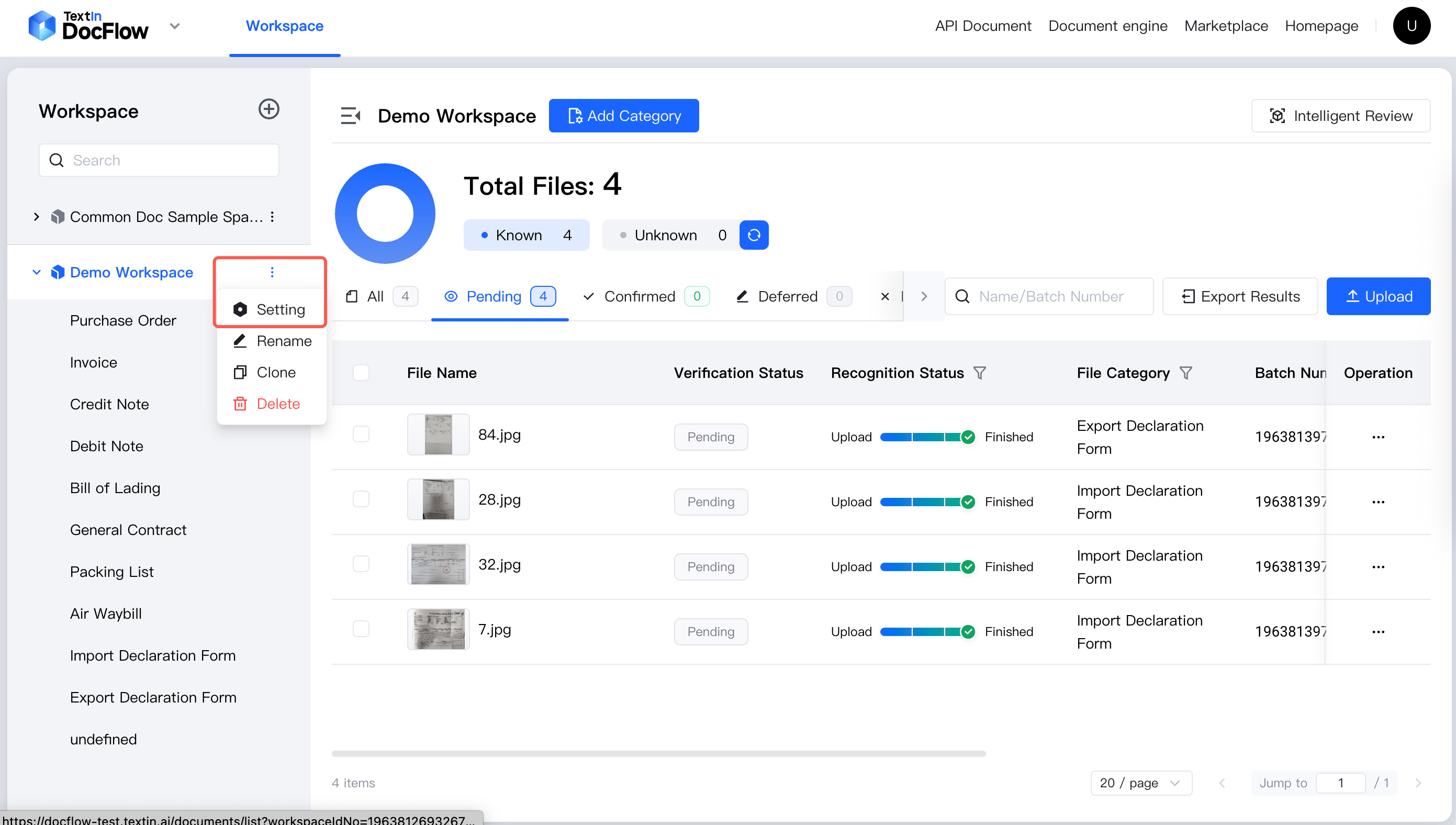
workspace_id を確認します。コピーアイコンをクリックすると直接コピーできます。
repo_id の取得方法
ステップ 1:対象ワークスペースに入り、右上の「スマートレビュー」ボタンをクリックします。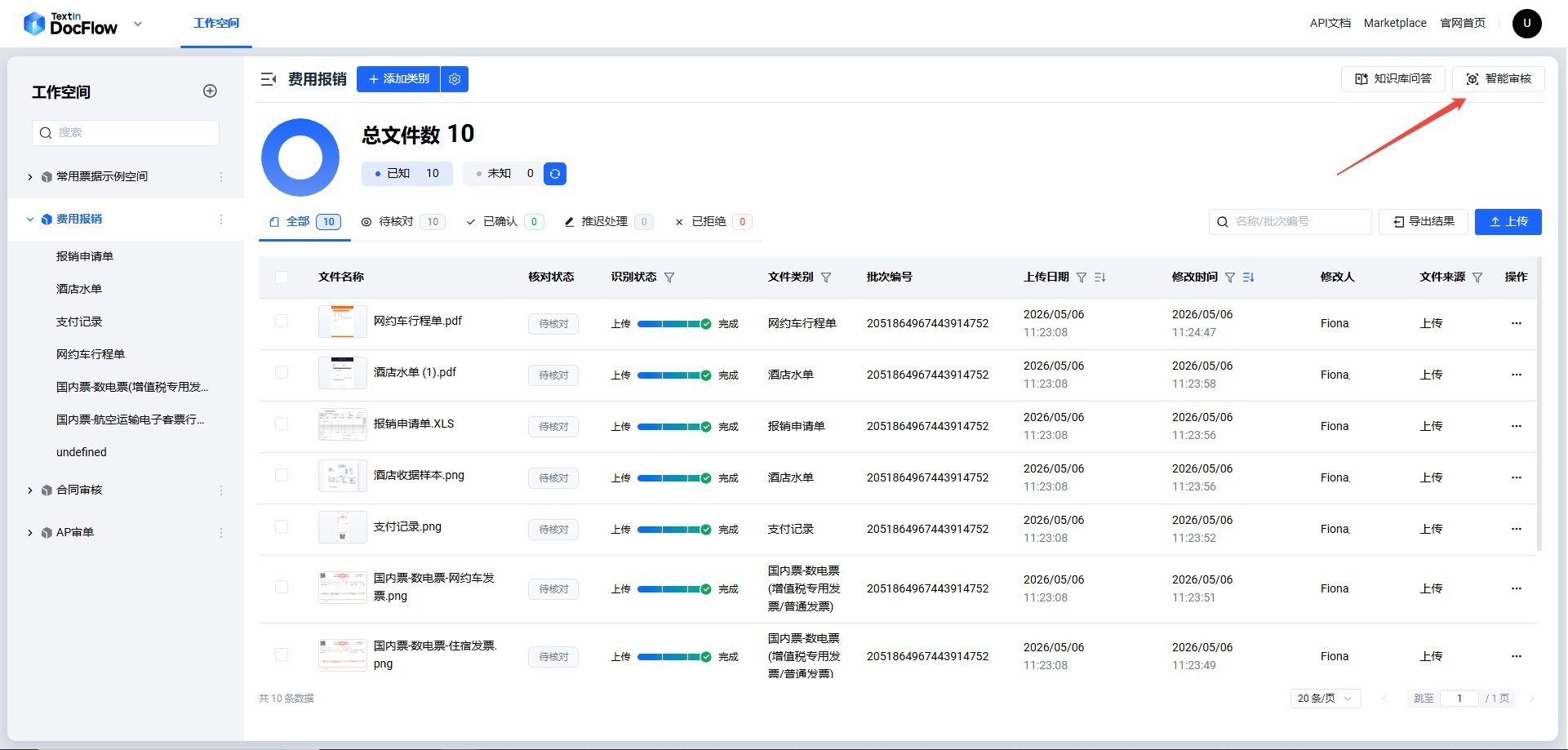
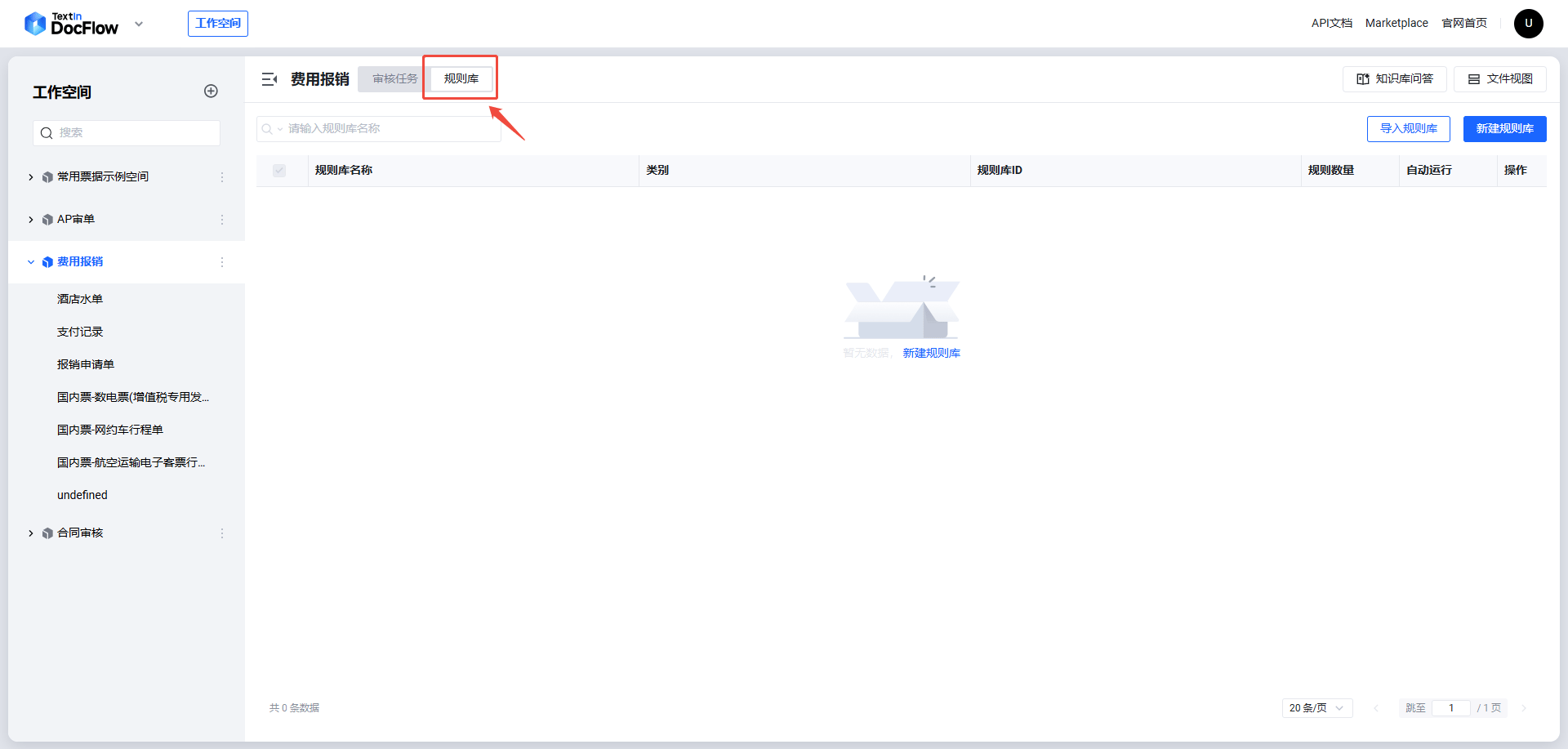
repo_id です。
03 コード構成
この例は日常処理に必要な 3 つのステップ のみを含み、コード量はゼロから設定する版より約 60% 少なくなります。2 種類の関数
REST API 呼び出し関数 — 各関数は API エンドポイントを直接ラップします:| 関数(Python) | メソッド(Java) | 対応する API エンドポイント | 説明 |
|---|---|---|---|
upload_file | uploadFile | POST /file/upload | 非同期でファイルをアップロードし、batch_number を返します。結果取得にはポーリングが必要です |
upload_file_sync | uploadFileSync | POST /file/upload/sync | 同期でファイルをアップロードし、抽出結果を直接返します。ポーリングは不要です |
submit_review_task | submitReviewTask | POST /review/task/submit | レビュータスクを送信し、レビュー task_id を返します |
| 関数(Python) | メソッド(Java) | 役割 |
|---|---|---|
_headers | authHeaders | 認証リクエストヘッダーを構築 |
_check | checkResponse | レスポンス code を検証し、例外処理を統一 |
_mime | mimeType | 拡張子から MIME タイプを推定 |
wait_for_result | waitForResult | ループでポーリング file/fetch、抽出完了を待機 |
display_result | displayResult | 抽出結果を整形して出力 |
wait_for_review | waitForReview | ループでポーリング review/task/result、レビュー完了を待機 |
display_review_result | displayReviewResult | レビュー結果を整形して出力 |
ステップ別コード説明
ステップ 1:処理対象ファイルをアップロード
ステップ 1:処理対象ファイルをアップロード
DocFlow は 2 種類のアップロードモードを提供します:
- 非同期アップロード(
file/upload):batch_numberを返します。ステップ 2 でfile/fetchをポーリングして抽出結果を取得します。一括アップロード後にまとめてポーリングするシーンに適しています。 - 同期アップロード(
file/upload/sync):認識完了までリクエストが待機し、抽出結果を直接返します(構造はfile/fetchと同じ)。ポーリングは不要で、ステップ 2 を省略できます。単一ファイルのリアルタイム処理に適しています。
方法 1:非同期アップロード(ステップ 2 のポーリングが必要)
- Python
- Java
def upload_file(workspace_id: str, file_path: str) -> str:
"""処理対象ファイルをワークスペースにアップロードし、batch_number を返します。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/upload"
with open(file_path, "rb") as f:
resp = requests.post(url,
params={"workspace_id": workspace_id},
files={"file": (os.path.basename(file_path), f, _mime(file_path))},
headers=_headers(), timeout=60)
batch_number = _check(resp, "ファイルをアップロード")["result"]["batch_number"]
print(f"[ステップ1] ファイルアップロード成功 name={os.path.basename(file_path)}"
f" batch_number={batch_number}")
return batch_number
# 呼び出し例: 今回の精算パッケージに含まれるすべての書類を一括アップロード
file_paths = [
os.path.join(FILES_DIR, "sample_expense_form.xls"),
os.path.join(FILES_DIR, "sample_hotel_receipt.png"),
os.path.join(FILES_DIR, "sample_payment_record.pdf"),
]
batch_numbers = [upload_file(WORKSPACE_ID, p) for p in file_paths]
public static String uploadFile(String workspaceId, String filePath) throws IOException {
File file = new File(filePath);
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/upload")
.newBuilder().addQueryParameter("workspace_id", workspaceId).build();
MultipartBody body = new MultipartBody.Builder().setType(MultipartBody.FORM)
.addFormDataPart("file", file.getName(),
RequestBody.create(file, MediaType.get(mimeType(file.getName()))))
.build();
Request req = new Request.Builder().url(url).headers(authHeaders()).post(body).build();
try (Response resp = HTTP.newCall(req).execute()) {
String batchNumber = checkResponse(resp.body().string(), "ファイルをアップロード")
.getAsJsonObject("result").get("batch_number").getAsString();
System.out.println("[ステップ1] ファイルアップロード成功 name=" + file.getName()
+ " batch_number=" + batchNumber);
return batchNumber;
}
}
// 呼び出し例: 今回の精算パッケージに含まれるすべての書類を一括アップロード
String[] filePaths = {
FILES_DIR + "/sample_expense_form.xls",
FILES_DIR + "/sample_hotel_receipt.png",
FILES_DIR + "/sample_payment_record.pdf"
};
List<String> batchNumbers = new ArrayList<>();
for (String path : filePaths) batchNumbers.add(uploadFile(WORKSPACE_ID, path));
方法 2:同期アップロード(抽出結果を直接返す、ステップ 2 を省略)
- Python
- Java
def upload_file_sync(workspace_id: str, file_path: str) -> dict:
"""同期アップロード:抽出結果を直接返す、ポーリング不要。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/upload/sync"
with open(file_path, "rb") as f:
resp = requests.post(url,
params={"workspace_id": workspace_id},
files={"file": (os.path.basename(file_path), f, _mime(file_path))},
headers=_headers(), timeout=300)
data = _check(resp, "ファイルを同期アップロード")
return data["result"]["files"][0] # 戻り値構造は file/fetch と同じ
# 呼び出し例:同期アップロードして抽出結果を直接取得
raw_results = [upload_file_sync(WORKSPACE_ID, p) for p in file_paths]
public static JsonObject uploadFileSync(String workspaceId, String filePath) throws IOException {
File file = new File(filePath);
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/upload/sync")
.newBuilder().addQueryParameter("workspace_id", workspaceId).build();
MultipartBody body = new MultipartBody.Builder().setType(MultipartBody.FORM)
.addFormDataPart("file", file.getName(),
RequestBody.create(file, MediaType.get(mimeType(file.getName()))))
.build();
Request req = new Request.Builder().url(url).headers(authHeaders()).post(body).build();
try (Response resp = HTTP.newCall(req).execute()) {
return checkResponse(resp.body().string(), "ファイルを同期アップロード")
.getAsJsonObject("result").getAsJsonArray("files")
.get(0).getAsJsonObject();
}
}
// 呼び出し例:同期アップロードして抽出結果を直接取得
String[] filePaths = {
FILES_DIR + "/sample_expense_form.xls",
FILES_DIR + "/sample_hotel_receipt.png",
FILES_DIR + "/sample_payment_record.pdf"
};
List<JsonObject> rawResults = new ArrayList<>();
for (String path : filePaths) rawResults.add(uploadFileSync(WORKSPACE_ID, path));
ステップ 2:抽出結果を取得(同期アップロード使用時は省略可能)
ステップ 2:抽出結果を取得(同期アップロード使用時は省略可能)
ステップ 1 で同期アップロード
file/upload/sync を使用した場合、抽出結果はすでに取得済みのため、このステップは省略できます。wait_for_result は file/fetch を 3 秒ごとにポーリングし、recognition_status が 1(成功)になるまで待機します。返されるファイル結果には task_id が含まれ、後続のレビューステップで使用します。- Python
- Java
def wait_for_result(workspace_id: str, batch_number: str,
timeout: int = 120, interval: int = 3) -> dict:
"""ファイル処理の完了をポーリングで待機し、task_id を含むファイル結果を返します。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/fetch"
deadline = time.time() + timeout
print(f"[ステップ2] 待機処理結果(batch_number={batch_number})", end="", flush=True)
while time.time() < deadline:
resp = requests.get(url,
params={"workspace_id": workspace_id, "batch_number": batch_number},
headers=_headers(), timeout=30)
files = _check(resp, "処理結果を取得").get("result", {}).get("files", [])
if files:
status = files[0].get("recognition_status")
if status == 1:
print(" 完了")
return files[0] # task_id を含み、後続のレビューで使用します
elif status == 2:
raise RuntimeError(f"ファイル処理失敗: {files[0].get('failure_causes')}")
print(".", end="", flush=True)
time.sleep(interval)
raise TimeoutError("待機タイムアウト")
# 呼び出し例(後続レビュー用に task_id を収集)
raw_results = []
for batch_number in batch_numbers:
result = wait_for_result(WORKSPACE_ID, batch_number)
raw_results.append(result)
display_result(result) # 任意:抽出詳細を出力
public static JsonObject waitForResult(String workspaceId, String batchNumber,
int timeoutSec, int intervalSec) throws IOException, InterruptedException {
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/fetch")
.newBuilder().addQueryParameter("workspace_id", workspaceId)
.addQueryParameter("batch_number", batchNumber).build();
long deadline = System.currentTimeMillis() + (long) timeoutSec * 1000;
System.out.print("[ステップ2] 待機処理結果(batch_number=" + batchNumber + ")");
while (System.currentTimeMillis() < deadline) {
Request req = new Request.Builder().url(url).headers(authHeaders()).get().build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject data = checkResponse(resp.body().string(), "処理結果を取得");
JsonArray files = data.getAsJsonObject("result").getAsJsonArray("files");
if (files != null && files.size() > 0) {
JsonObject file = files.get(0).getAsJsonObject();
int status = file.get("recognition_status").getAsInt();
if (status == 1) { System.out.println(" 完了"); return file; }
if (status == 2) throw new RuntimeException("ファイル処理失敗");
}
}
System.out.print(".");
Thread.sleep((long) intervalSec * 1000);
}
throw new RuntimeException("待機タイムアウト");
}
// 呼び出し例
List<JsonObject> rawResults = new ArrayList<>();
for (String bn : batchNumbers) {
JsonObject result = waitForResult(WORKSPACE_ID, bn, 120, 3);
rawResults.add(result);
displayResult(result); // 任意:抽出詳細を出力
}
recognition_status の値は、0 = 処理中、1 = 成功、2 = 失敗を表します。ファイルサイズが大きい場合やページ数が多い場合は処理時間が長くなるため、必要に応じて timeout パラメータを大きくしてください。ステップ 3:レビュータスクを送信して結果を取得
ステップ 3:レビュータスクを送信して結果を取得
ステップ 2 の抽出結果から レビュー結果
task_id を取得し、レビュー API に渡します。既存の規則リポジトリ(repo_id)を指定してレビュータスクを送信します。レビュータスクは非同期で実行されるため、送信後に結果をポーリングします。- Python
- Java
def submit_review_task(workspace_id: str, name: str,
repo_id: str, extract_task_ids: list) -> str:
"""レビュータスクを送信し、レビュー task_id を返します。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/review/task/submit"
payload = {
"workspace_id": workspace_id,
"name": name,
"repo_id": repo_id,
"extract_task_ids": extract_task_ids,
}
resp = requests.post(url, json=payload, headers=_headers(), timeout=30)
task_id = _check(resp, "送信レビュータスク")["result"]["task_id"]
print(f"[ステップ3] レビュータスク送信成功 task_id={task_id}")
return task_id
def wait_for_review(workspace_id: str, task_id: str,
timeout: int = 300, interval: int = 5) -> dict:
"""ポーリングレビュー完了を待機、返すレビュー結果。"""
url = f"{BASE_URL}/api/app-api/sip/platform/v2/review/task/result"
payload = {"workspace_id": workspace_id, "task_id": task_id}
deadline = time.time() + timeout
print(f"[ステップ3] 待機レビュー結果(task_id={task_id})", end="", flush=True)
while time.time() < deadline:
resp = requests.post(url, json=payload, headers=_headers(), timeout=30)
result = _check(resp, "取得レビュー結果").get("result", {})
# 終了ステータス:1=レビュー合格、2=レビュー失敗、4=レビュー不合格、7=認識失敗
if result.get("status") in (1, 2, 4, 7):
print(" 完了")
return result
print(".", end="", flush=True)
time.sleep(interval)
raise TimeoutError("待機レビュー結果タイムアウト")
# 呼び出し例
task_name = f"経費精算レビュー_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
extract_task_ids = [r.get("task_id") for r in raw_results if r.get("task_id")]
review_task_id = submit_review_task(WORKSPACE_ID, task_name, REPO_ID, extract_task_ids)
review_result = wait_for_review(WORKSPACE_ID, review_task_id)
display_review_result(review_result)
public static String submitReviewTask(String workspaceId, String name,
String repoId, List<String> extractTaskIds) throws IOException {
JsonObject payload = new JsonObject();
payload.addProperty("workspace_id", workspaceId);
payload.addProperty("name", name);
payload.addProperty("repo_id", repoId);
JsonArray ids = new JsonArray();
extractTaskIds.forEach(ids::add);
payload.add("extract_task_ids", ids);
Request req = new Request.Builder()
.url(BASE_URL + "/api/app-api/sip/platform/v2/review/task/submit")
.headers(authHeaders())
.post(RequestBody.create(GSON.toJson(payload), JSON_TYPE)).build();
try (Response resp = HTTP.newCall(req).execute()) {
String taskId = checkResponse(resp.body().string(), "送信レビュータスク")
.getAsJsonObject("result").get("task_id").getAsString();
System.out.println("[ステップ3] レビュータスク送信成功 task_id=" + taskId);
return taskId;
}
}
public static JsonObject waitForReview(String workspaceId, String taskId,
int timeoutSec, int intervalSec) throws IOException, InterruptedException {
JsonObject payload = new JsonObject();
payload.addProperty("workspace_id", workspaceId);
payload.addProperty("task_id", taskId);
long deadline = System.currentTimeMillis() + (long) timeoutSec * 1000;
System.out.print("[ステップ3] 待機レビュー結果(task_id=" + taskId + ")");
while (System.currentTimeMillis() < deadline) {
Request req = new Request.Builder()
.url(BASE_URL + "/api/app-api/sip/platform/v2/review/task/result")
.headers(authHeaders())
.post(RequestBody.create(GSON.toJson(payload), JSON_TYPE)).build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject result = checkResponse(resp.body().string(), "取得レビュー結果")
.getAsJsonObject("result");
int status = result.get("status").getAsInt();
// 終了ステータス:1=レビュー合格、2=レビュー失敗、4=レビュー不合格、7=認識失敗
if (status == 1 || status == 2 || status == 4 || status == 7) {
System.out.println(" 完了");
return result;
}
}
System.out.print(".");
Thread.sleep((long) intervalSec * 1000);
}
throw new RuntimeException("待機レビュー結果タイムアウト");
}
// 呼び出し例
String taskName = "経費精算レビュー_"
+ new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());
List<String> extractTaskIds = new ArrayList<>();
for (JsonObject r : rawResults) {
if (r.has("task_id")) extractTaskIds.add(r.get("task_id").getAsString());
}
String reviewTaskId = submitReviewTask(WORKSPACE_ID, taskName, REPO_ID, extractTaskIds);
JsonObject reviewResult = waitForReview(WORKSPACE_ID, reviewTaskId, 300, 5);
displayReviewResult(reviewResult);
status 含义:| ステータス值 | 含义 |
|---|---|
1 | レビュー合格 — 所有規則均合格 |
4 | レビュー不合格 — 存在高リスク或中リスク規則命中 |
2 | レビュー失敗 — 系统内部错误 |
7 | 認識失敗 — ファイル認識阶段出错 |
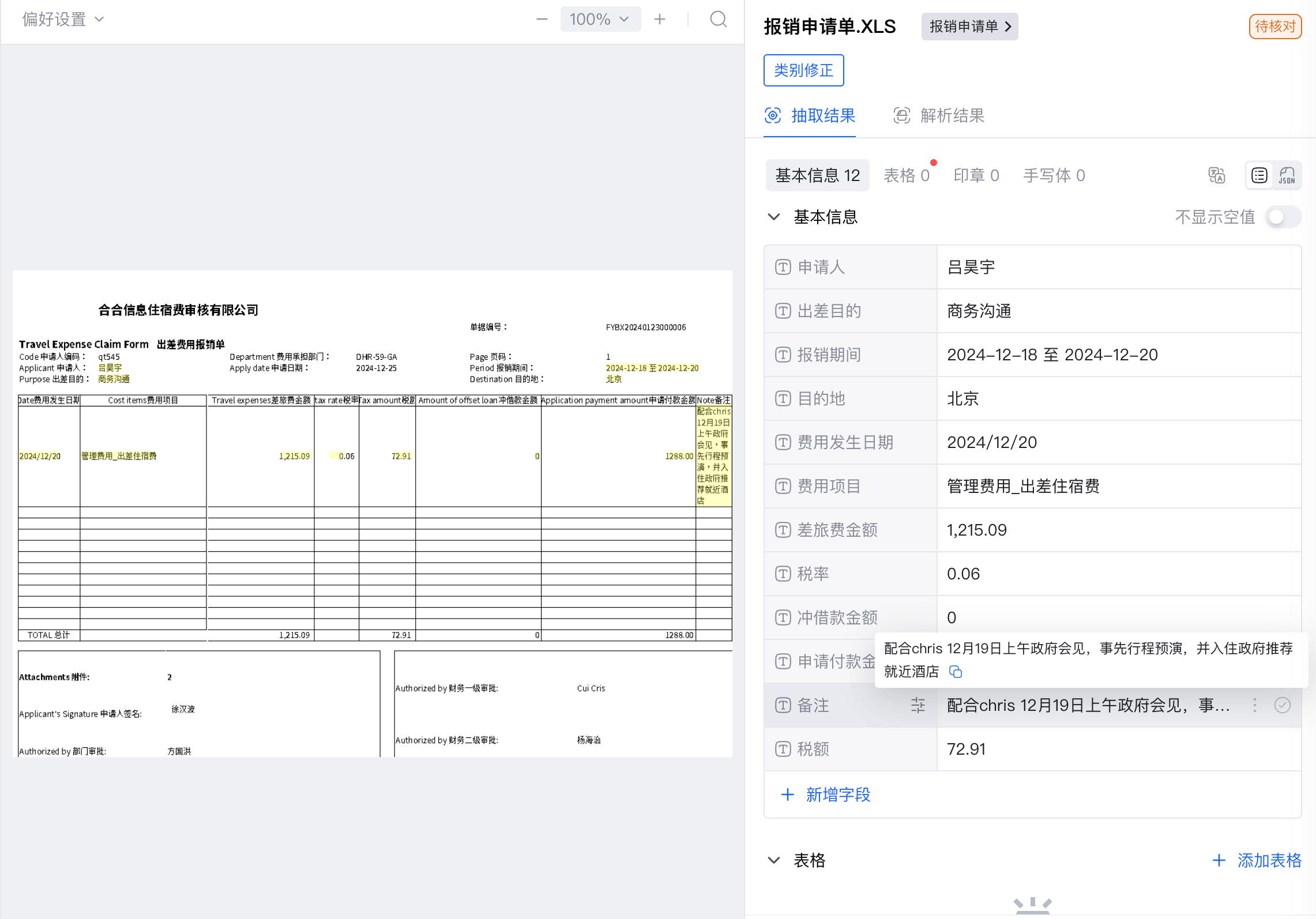
抽出結果の例
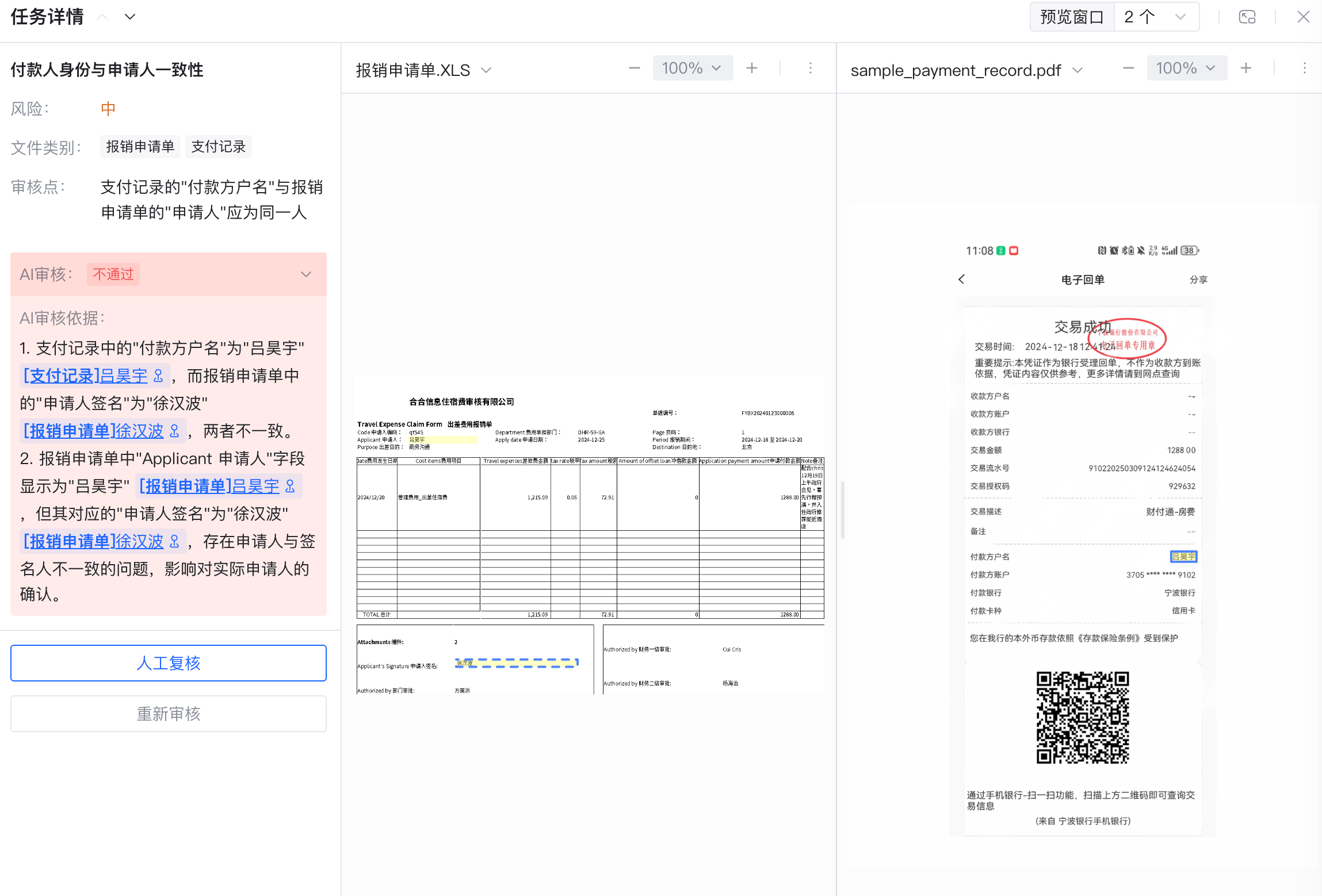
レビュー結果の例
04 完全な例コード
- Python
- Java
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
DocFlow 経費精算シナリオ例(設定済み版)
适用于ワークスペース、ファイルカテゴリ、レビュー規則リポジトリ已設定済み的シナリオ。
フロー:
1. 処理対象ファイルをアップロード
2. ポーリング抽出結果を取得(分類認識 + フィールド抽出)
3. レビュータスクを送信し、レビュー結論を取得します
依存関係:pip install requests
"""
import json
import os
import time
from datetime import datetime
import requests
# ============================================================
# 設定項目 - 実際の値に置き換えてください
# ============================================================
APP_ID = "your-app-id" # TextIn コンソールの x-ti-app-id
SECRET_CODE = "your-secret-code" # TextIn コンソールの x-ti-secret-code
WORKSPACE_ID = "your-workspace-id" # 已作成的ワークスペース ID
REPO_ID = "your-repo-id" # 已設定的レビュー規則リポジトリ ID
BASE_URL = "https://docflow.textin.ai"
FILES_DIR = os.path.join(
os.path.dirname(os.path.abspath(__file__)),
"..", "sample_files", "expense_reimbursement"
)
# ============================================================
# 補助関数
# ============================================================
def _headers() -> dict:
return {"x-ti-app-id": APP_ID, "x-ti-secret-code": SECRET_CODE}
def _check(resp: requests.Response, action: str) -> dict:
data = resp.json()
if data.get("code") != 200:
raise RuntimeError(f"{action} 失敗(code={data.get('code')}): {data}")
return data
def _mime(file_path: str) -> str:
ext = os.path.splitext(file_path)[1].lower()
return {
".png": "image/png",
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".xls": "application/vnd.ms-excel",
".xlsx": "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
".pdf": "application/pdf",
}.get(ext, "application/octet-stream")
def display_result(file_obj: dict) -> None:
"""整形して出力单个ファイル的分類とフィールド抽出結果。"""
name = file_obj.get("file_name", "")
cat = file_obj.get("category_name", "未認識")
fields = file_obj.get("fields", [])
tables = file_obj.get("tables", [])
print("=" * 60)
print(f"ファイル名 : {name}")
print(f"分類結果 : {cat}\n")
if fields:
print("── 普通フィールド " + "─" * 30)
for f in fields:
print(f" {f['name']:<20}: {f.get('value', '')}")
for t in tables:
print(f"\n── テーブル:{t.get('name', '')} " + "─" * 20)
rows = t.get("rows", [])
if rows:
headers = [c.get("name", "") for c in rows[0].get("cells", [])]
print(" " + " | ".join(f"{h:<12}" for h in headers))
print(" " + "-" * (15 * len(headers)))
for row in rows:
vals = [c.get("value", "") for c in row.get("cells", [])]
print(" " + " | ".join(f"{v:<12}" for v in vals))
print()
def display_review_result(result: dict) -> None:
"""整形して出力レビュー結論。"""
status_map = {1: "✅ レビュー合格", 2: "❌ レビュー失敗", 4: "⚠️ レビュー不合格", 7: "❌ 認識失敗"}
print("=" * 60)
print(f" レビュー結論:{status_map.get(result.get('status'), '不明')}")
stats = result.get("statistics", {})
print(f" 規則集計:合格 {stats.get('passed', 0)} 条 / "
f"不合格 {stats.get('failed', 0)} 条 / "
f"スキップ {stats.get('skipped', 0)} 条")
for group in result.get("groups", []):
print(f"\n 規則グループ:{group.get('name', '')}")
for rule in group.get("rules", []):
icon = "✅" if rule.get("status") == 1 else "⚠️ "
print(f" {icon} {rule.get('name', '')}")
if rule.get("message"):
print(f" → {rule['message']}")
print()
# ============================================================
# ステップ 1:処理対象ファイルをアップロード
# REST API: POST /api/app-api/sip/platform/v2/file/upload
# ============================================================
def upload_file(workspace_id: str, file_path: str) -> str:
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/upload"
with open(file_path, "rb") as f:
resp = requests.post(url,
params={"workspace_id": workspace_id},
files={"file": (os.path.basename(file_path), f, _mime(file_path))},
headers=_headers(), timeout=60)
batch_number = _check(resp, "ファイルをアップロード")["result"]["batch_number"]
print(f"[ステップ1] ファイルアップロード成功 name={os.path.basename(file_path)}"
f" batch_number={batch_number}")
return batch_number
# ============================================================
# ステップ 2:ポーリング抽出結果を取得
# REST API: GET /api/app-api/sip/platform/v2/file/fetch
# ============================================================
def wait_for_result(workspace_id: str, batch_number: str,
timeout: int = 120, interval: int = 3) -> dict:
url = f"{BASE_URL}/api/app-api/sip/platform/v2/file/fetch"
deadline = time.time() + timeout
print(f"[ステップ2] 待機処理結果(batch_number={batch_number})", end="", flush=True)
while time.time() < deadline:
resp = requests.get(url,
params={"workspace_id": workspace_id, "batch_number": batch_number},
headers=_headers(), timeout=30)
files = _check(resp, "処理結果を取得").get("result", {}).get("files", [])
if files:
status = files[0].get("recognition_status")
if status == 1:
print(" 完了")
return files[0]
elif status == 2:
raise RuntimeError(f"ファイル処理失敗: {files[0].get('failure_causes')}")
print(".", end="", flush=True)
time.sleep(interval)
raise TimeoutError("待機タイムアウト")
# ============================================================
# ステップ 3:送信レビュータスク
# REST API: POST /api/app-api/sip/platform/v2/review/task/submit
# ============================================================
def submit_review_task(workspace_id: str, name: str,
repo_id: str, extract_task_ids: list) -> str:
url = f"{BASE_URL}/api/app-api/sip/platform/v2/review/task/submit"
payload = {
"workspace_id": workspace_id,
"name": name,
"repo_id": repo_id,
"extract_task_ids": extract_task_ids,
}
resp = requests.post(url, json=payload, headers=_headers(), timeout=30)
task_id = _check(resp, "送信レビュータスク")["result"]["task_id"]
print(f"[ステップ3] レビュータスク送信成功 task_id={task_id}")
return task_id
# ============================================================
# ステップ 4:ポーリング取得レビュー結果
# REST API: POST /api/app-api/sip/platform/v2/review/task/result
# ============================================================
def wait_for_review(workspace_id: str, task_id: str,
timeout: int = 300, interval: int = 5) -> dict:
url = f"{BASE_URL}/api/app-api/sip/platform/v2/review/task/result"
payload = {"workspace_id": workspace_id, "task_id": task_id}
deadline = time.time() + timeout
print(f"[ステップ3] 待機レビュー結果(task_id={task_id})", end="", flush=True)
while time.time() < deadline:
resp = requests.post(url, json=payload, headers=_headers(), timeout=30)
result = _check(resp, "取得レビュー結果").get("result", {})
if result.get("status") in (1, 2, 4, 7):
print(" 完了")
return result
print(".", end="", flush=True)
time.sleep(interval)
raise TimeoutError("待機レビュー結果タイムアウト")
# ============================================================
# 主フロー
# ============================================================
def main():
print("=" * 60)
print(" DocFlow 経費精算シナリオ例(設定済み版)")
print("=" * 60)
print(f"ワークスペース: {WORKSPACE_ID}")
print(f"規則リポジトリ: {REPO_ID}\n")
# ステップ 1:ファイルをアップロード
print("開始処理対象ファイルをアップロード...")
file_paths = [
os.path.join(FILES_DIR, "sample_expense_form.xls"),
os.path.join(FILES_DIR, "sample_hotel_receipt.png"),
os.path.join(FILES_DIR, "sample_payment_record.pdf"),
]
batch_numbers = [upload_file(WORKSPACE_ID, p) for p in file_paths]
# ステップ 2:抽出結果を取得
print("\n開始処理結果を取得...")
raw_results = []
for batch_number in batch_numbers:
result = wait_for_result(WORKSPACE_ID, batch_number)
raw_results.append(result)
display_result(result)
# ステップ 3:送信レビュータスク
print("\n開始レビュー...")
task_name = f"経費精算レビュー_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
extract_task_ids = [r.get("task_id") for r in raw_results if r.get("task_id")]
review_task_id = submit_review_task(WORKSPACE_ID, task_name, REPO_ID, extract_task_ids)
# ステップ 4:取得レビュー結果
review_result = wait_for_review(WORKSPACE_ID, review_task_id)
display_review_result(review_result)
if __name__ == "__main__":
main()
package com.docflow;
import com.google.gson.*;
import okhttp3.*;
import java.io.*;
import java.text.SimpleDateFormat;
import java.util.*;
/**
* DocFlow 経費精算シナリオ例(設定済み版)
*
* 适用于ワークスペース、ファイルカテゴリ、レビュー規則リポジトリ已設定済み的シナリオ。
* フロー:
* 1. 処理対象ファイルをアップロード
* 2. ポーリング抽出結果を取得(分類認識 + フィールド抽出)
* 3. レビュータスクを送信し、レビュー結論を取得します
*
* 依存関係:okhttp3、gson(见 pom.xml)
*/
public class ExpenseReimbursementConfigured {
// ============================================================
// 設定項目 - 実際の値に置き換えてください
// ============================================================
private static final String APP_ID = "your-app-id";
private static final String SECRET_CODE = "your-secret-code";
private static final String WORKSPACE_ID = "your-workspace-id";
private static final String REPO_ID = "your-repo-id";
private static final String BASE_URL = "https://docflow.textin.ai";
private static final String FILES_DIR = "../sample_files/expense_reimbursement";
private static final OkHttpClient HTTP = new OkHttpClient.Builder()
.callTimeout(java.time.Duration.ofSeconds(60)).build();
private static final Gson GSON = new Gson();
private static final MediaType JSON_TYPE = MediaType.get("application/json; charset=utf-8");
// ============================================================
// ユーティリティメソッド
// ============================================================
private static Headers authHeaders() {
return new Headers.Builder()
.add("x-ti-app-id", APP_ID)
.add("x-ti-secret-code", SECRET_CODE)
.build();
}
private static JsonObject checkResponse(String body, String action) {
JsonObject obj = JsonParser.parseString(body).getAsJsonObject();
if (obj.get("code").getAsInt() != 200)
throw new RuntimeException(action + " 失敗: " + body);
return obj;
}
private static String mimeType(String fileName) {
String ext = fileName.substring(fileName.lastIndexOf('.')).toLowerCase();
switch (ext) {
case ".png": return "image/png";
case ".jpg":
case ".jpeg": return "image/jpeg";
case ".xls": return "application/vnd.ms-excel";
case ".xlsx": return "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet";
case ".pdf": return "application/pdf";
default: return "application/octet-stream";
}
}
// ============================================================
// ステップ 1:処理対象ファイルをアップロード
// ============================================================
public static String uploadFile(String workspaceId, String filePath) throws IOException {
File file = new File(filePath);
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/upload")
.newBuilder().addQueryParameter("workspace_id", workspaceId).build();
MultipartBody body = new MultipartBody.Builder().setType(MultipartBody.FORM)
.addFormDataPart("file", file.getName(),
RequestBody.create(file, MediaType.get(mimeType(file.getName()))))
.build();
Request req = new Request.Builder().url(url).headers(authHeaders()).post(body).build();
try (Response resp = HTTP.newCall(req).execute()) {
String batchNumber = checkResponse(resp.body().string(), "ファイルをアップロード")
.getAsJsonObject("result").get("batch_number").getAsString();
System.out.println("[ステップ1] ファイルアップロード成功 name=" + file.getName()
+ " batch_number=" + batchNumber);
return batchNumber;
}
}
// ============================================================
// ステップ 2:ポーリング抽出結果を取得
// ============================================================
public static JsonObject waitForResult(String workspaceId, String batchNumber,
int timeoutSec, int intervalSec) throws IOException, InterruptedException {
HttpUrl url = HttpUrl.parse(BASE_URL + "/api/app-api/sip/platform/v2/file/fetch")
.newBuilder().addQueryParameter("workspace_id", workspaceId)
.addQueryParameter("batch_number", batchNumber).build();
long deadline = System.currentTimeMillis() + (long) timeoutSec * 1000;
System.out.print("[ステップ2] 待機処理結果(batch_number=" + batchNumber + ")");
while (System.currentTimeMillis() < deadline) {
Request req = new Request.Builder().url(url).headers(authHeaders()).get().build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject data = checkResponse(resp.body().string(), "処理結果を取得");
JsonArray files = data.getAsJsonObject("result").getAsJsonArray("files");
if (files != null && files.size() > 0) {
JsonObject file = files.get(0).getAsJsonObject();
int status = file.get("recognition_status").getAsInt();
if (status == 1) { System.out.println(" 完了"); return file; }
if (status == 2) throw new RuntimeException("ファイル処理失敗");
}
}
System.out.print(".");
Thread.sleep((long) intervalSec * 1000);
}
throw new RuntimeException("待機タイムアウト");
}
// ============================================================
// ステップ 3:送信レビュータスク
// ============================================================
public static String submitReviewTask(String workspaceId, String name,
String repoId, List<String> extractTaskIds) throws IOException {
JsonObject payload = new JsonObject();
payload.addProperty("workspace_id", workspaceId);
payload.addProperty("name", name);
payload.addProperty("repo_id", repoId);
JsonArray ids = new JsonArray();
extractTaskIds.forEach(ids::add);
payload.add("extract_task_ids", ids);
Request req = new Request.Builder()
.url(BASE_URL + "/api/app-api/sip/platform/v2/review/task/submit")
.headers(authHeaders())
.post(RequestBody.create(GSON.toJson(payload), JSON_TYPE)).build();
try (Response resp = HTTP.newCall(req).execute()) {
String taskId = checkResponse(resp.body().string(), "送信レビュータスク")
.getAsJsonObject("result").get("task_id").getAsString();
System.out.println("[ステップ3] レビュータスク送信成功 task_id=" + taskId);
return taskId;
}
}
// ============================================================
// ステップ 4:ポーリング取得レビュー結果
// ============================================================
public static JsonObject waitForReview(String workspaceId, String taskId,
int timeoutSec, int intervalSec) throws IOException, InterruptedException {
JsonObject payload = new JsonObject();
payload.addProperty("workspace_id", workspaceId);
payload.addProperty("task_id", taskId);
long deadline = System.currentTimeMillis() + (long) timeoutSec * 1000;
System.out.print("[ステップ3] 待機レビュー結果(task_id=" + taskId + ")");
while (System.currentTimeMillis() < deadline) {
Request req = new Request.Builder()
.url(BASE_URL + "/api/app-api/sip/platform/v2/review/task/result")
.headers(authHeaders())
.post(RequestBody.create(GSON.toJson(payload), JSON_TYPE)).build();
try (Response resp = HTTP.newCall(req).execute()) {
JsonObject result = checkResponse(resp.body().string(), "取得レビュー結果")
.getAsJsonObject("result");
int status = result.get("status").getAsInt();
if (status == 1 || status == 2 || status == 4 || status == 7) {
System.out.println(" 完了");
return result;
}
}
System.out.print(".");
Thread.sleep((long) intervalSec * 1000);
}
throw new RuntimeException("待機レビュー結果タイムアウト");
}
// ============================================================
// 主フロー
// ============================================================
public static void main(String[] args) throws Exception {
System.out.println("=".repeat(60));
System.out.println(" DocFlow 経費精算シナリオ例(設定済み版)");
System.out.println("=".repeat(60));
System.out.println("ワークスペース: " + WORKSPACE_ID);
System.out.println("規則リポジトリ: " + REPO_ID + "\n");
// ステップ 1:ファイルをアップロード
System.out.println("開始処理対象ファイルをアップロード...");
String[] filePaths = {
FILES_DIR + "/sample_expense_form.xls",
FILES_DIR + "/sample_hotel_receipt.png",
FILES_DIR + "/sample_payment_record.pdf"
};
List<String> batchNumbers = new ArrayList<>();
for (String path : filePaths) batchNumbers.add(uploadFile(WORKSPACE_ID, path));
// ステップ 2:抽出結果を取得
System.out.println("\n開始処理結果を取得...");
List<JsonObject> rawResults = new ArrayList<>();
for (String bn : batchNumbers) {
rawResults.add(waitForResult(WORKSPACE_ID, bn, 120, 3));
}
// ステップ 3:送信レビュータスク
System.out.println("\n開始レビュー...");
String taskName = "経費精算レビュー_"
+ new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());
List<String> extractTaskIds = new ArrayList<>();
for (JsonObject r : rawResults) {
if (r.has("task_id")) extractTaskIds.add(r.get("task_id").getAsString());
}
String reviewTaskId = submitReviewTask(WORKSPACE_ID, taskName, REPO_ID, extractTaskIds);
// ステップ 4:取得レビュー結果
JsonObject reviewResult = waitForReview(WORKSPACE_ID, reviewTaskId, 300, 5);
System.out.println("\nレビュー完了、ステータスコード: " + reviewResult.get("status").getAsInt());
}
}
05 完全な例コードダウンロード
完全な実行可能コード(Python 版、Java 版)は、ドキュメントリポジトリのexamples/ ディレクトリに同梱されています:
examples/
├── python/
│ ├── expense_reimbursement_configured.py # Python 完全な例(設定済み版)
│ ├── requirements.txt
│ └── README.md
├── java/
│ ├── src/main/java/com/docflow/
│ │ └── ExpenseReimbursementConfigured.java # Java 完全な例(設定済み版)
│ ├── pom.xml
│ └── README.md
└── sample_files/
└── expense_reimbursement/
├── sample_expense_form.xls
├── sample_hotel_receipt.png
└── sample_payment_record.pdf
Python 例
確認 Python 完全な例コード
Java 例
確認 Java 完全な例コード
06 実行例
- Python
- Java
環境要件:Python 3.8+1. 依存関係をインストール2. 入力設定開き 3. 実行
cd examples/python
pip install -r requirements.txt
expense_reimbursement_configured.py、入力ファイル上部的設定項目:APP_ID = "your-app-id" # x-ti-app-id
SECRET_CODE = "your-secret-code" # x-ti-secret-code
WORKSPACE_ID = "your-workspace-id" # 已作成的ワークスペース ID
REPO_ID = "your-repo-id" # 已設定的レビュー規則リポジトリ ID
python expense_reimbursement_configured.py
環境要件:JDK 11+、Maven 3.6+1. 入力設定開き 2. ビルドして実行
src/main/java/com/docflow/ExpenseReimbursementConfigured.java、入力ファイル上部的設定項目:private static final String APP_ID = "your-app-id";
private static final String SECRET_CODE = "your-secret-code";
private static final String WORKSPACE_ID = "your-workspace-id";
private static final String REPO_ID = "your-repo-id";
cd examples/java
mvn clean package -q
java -jar target/expense-reimbursement-1.0.0.jar
実行に成功したら、DocFlow Web ページ にログインし、対象ワークスペースで各ファイルの分類結果、フィールド抽出結果、スマートレビュー結果を確認できます。コードの出力結果との照合にも役立ちます。
想定されるコンソール出力
============================================================
DocFlow 経費精算シナリオ例(設定済み版)
============================================================
ワークスペース: <workspace_id>
規則リポジトリ: <repo_id>
開始処理対象ファイルをアップロード...
[ステップ1] ファイルアップロード成功 name=sample_expense_form.xls batch_number=<batch_number>
[ステップ1] ファイルアップロード成功 name=sample_hotel_receipt.png batch_number=<batch_number>
[ステップ1] ファイルアップロード成功 name=sample_payment_record.pdf batch_number=<batch_number>
開始処理結果を取得...
[ステップ2] 待機処理結果(batch_number=<batch_number>)..... 完了
============================================================
ファイル名 : sample_expense_form.xls
分類結果 : 経費申請書
── 普通フィールド ──────────────────────────
申請者 : 吕昊宇
出張目的 : 商务沟通
精算期間 : 2024-12-18 至 2024-12-20
...
開始レビュー...
[ステップ3] レビュータスク送信成功 task_id=<task_id>
[ステップ3] 待機レビュー結果(task_id=<task_id>).. 完了
============================================================
レビュー結論:⚠️ レビュー不合格
規則集計:合格 6 条 / 不合格 2 条 / スキップ 0 条
規則グループ:経費申請書コンプライアンス性チェック
✅ 必須フィールド完全性チェック
⚠️ 行精算金額チェック
→ 第 2 行支払申請額超出出張費金額
...
07 結果説明
抽出結果
処理完了後、各ファイルの分類結果とフィールド抽出結果が返されます。フィールド抽出結果はdata.fields[] に格納され、各フィールドには key、value、座標情報 position が含まれます(原文のハイライト表示に利用できます)。
以下は、3 つのサンプルファイルに対する実際の API レスポンス例です(file/fetch から取得。一部の position 座標は省略しています)。
sample_expense_form.xls
sample_expense_form.xls
{
"name": "sample_expense_form.xls",
"format": "xls",
"category": "経費申請書",
"recognition_status": 1,
"duration_ms": 5316,
"data": {
"fields": [
{ "key": "備考", "value": "配合chris 12月19日上午政府会见、事先行程预演、并チェックイン政府推荐就近酒店" },
{ "key": "申請者", "value": "吕昊宇" },
{ "key": "出張目的", "value": "商务沟通" },
{ "key": "精算期間", "value": "2024-12-18 至 2024-12-20" },
{ "key": "税率", "value": "0.06" },
{ "key": "税額", "value": "30.06" }
],
"stamps": [],
"handwritings": []
}
}
sample_hotel_receipt.png
sample_hotel_receipt.png
{
"name": "sample_hotel_receipt.png",
"format": "png",
"category": "ホテル明細",
"recognition_status": 1,
"duration_ms": 6185,
"data": {
"fields": [
{ "key": "合計金額", "value": "1,288.00" },
{ "key": "チェックイン日付", "value": "2024-12-18" },
{ "key": "チェックアウト日付", "value": "2024-12-20" }
],
"items": [
[
{ "key": "日付", "value": "2024-12-18" },
{ "key": "費用タイプ", "value": "房费*Room Charge" },
{ "key": "金額", "value": "644.00" }
],
[
{ "key": "日付", "value": "2024-12-19" },
{ "key": "費用タイプ", "value": "房费*Room Charge" },
{ "key": "金額", "value": "644.00" }
]
],
"stamps": [
{
"text": "北京中■马哥华罗大酒店有限 請求書专用章",
"type": "其他",
"color": "红色",
"shape": "椭圆章"
}
],
"handwritings": []
}
}
sample_payment_record.pdf
sample_payment_record.pdf
{
"name": "sample_payment_record.pdf",
"format": "pdf",
"category": "支払記録",
"recognition_status": 1,
"duration_ms": 7203,
"data": {
"fields": [
{ "key": "取引説明", "value": "财付通-叶婆婆钵钵鸡" },
{ "key": "取引番号", "value": "910220250309124124624054" },
{ "key": "取引日時", "value": "2025-03-09 12:41:24" },
{ "key": "取引金額", "value": "240.00" },
{ "key": "支払銀行", "value": "宁波銀行" },
{ "key": "取引口座/支払方法", "value": "信用卡" },
{ "key": "支払人名義", "value": "吕昊宇" }
],
"stamps": [
{
"text": "宁波銀行股份有限公司 電子控え专用章",
"type": "其他",
"color": "红色",
"shape": "椭圆章"
}
],
"handwritings": []
}
}
レビュー結果
レビュー完了後、review/task/result API から次の情報を取得できます:
status:タスク全体のステータス(1=レビュー合格、4=レビュー不合格、2=レビュー失敗)statistics:規則合格数、不合格数汇总groups[].review_tasks[]:各規則的詳細レビュー結果、含む:review_result:この規則的レビュー結論reasoning:AI によるレビュー根拠の説明anchors:原文内で根拠となる座標位置(ハイライト表示に利用できます)
{
"task_id": "31415926",
"task_name": "経費精算レビュー",
"status": 4,
"statistics": { "pass_count": 5, "failure_count": 3, "error_count": 0 },
"groups": [
{
"group_name": "経費申請書コンプライアンス性チェック",
"review_tasks": [
{
"rule_name": "必須フィールド完全性チェック",
"risk_level": 10,
"review_result": 1,
"reasoning": "申請者、費用発生日、費用項目、支払申請額はいずれも入力済み、レビュー合格。"
},
{
"rule_name": "行精算金額チェック",
"risk_level": 10,
"review_result": 4,
"reasoning": "行支払申請額 1288.00 大于行出張費金額(税込)1215.09 + 税額 72.91 = 1288.00、など于上限、レビュー不合格。"
}
]
},
{
"group_name": "出張費用政策照合レビュー",
"review_tasks": [
{
"rule_name": "城市差标照合",
"risk_level": 20,
"review_result": 1,
"reasoning": "酒店あります北京(一线城市)、住宿単価 644.00 元/晚未超過 800 元/晚的基準、レビュー合格。"
}
]
},
{
"group_name": "複数文書クロスレビュー",
"review_tasks": [
{
"rule_name": "支払人身份と申請者整合性",
"risk_level": 20,
"review_result": 4,
"reasoning": "支払記録支払人名義"吕昊宇"と経費申請書申請者签名"徐汉波"一致しません、レビュー不合格。"
}
]
}
]
}